Last updated on June 28, 2022 by Bilson Simamora
Selain dengan kesan umum, kesamaan juga dapat dinilai berbasis atribut. Untuk pendekatan ini, penilaian kesamaan dilakukan secara tidak langsung atau diturunkan dari data variabel lain melalui mana kesamaan dapat disimpulan (derived similarity). Metoda ini disebut juga metoda decompositional, seperti dijelaskan di sini.
Misalkan kita ingin memetakan lima merek susu kental yang beredar di pasaran. Adapun atribut yang kita gunakan sebagai pembanding adalah rasa, aroma, kekentalan dan harga. Dengan skala numerik berskala tujuh kita memperoleh data seperti pada Tabel 1.
Tabel 1. Contoh Data Similarity berbasis Atribut
| Atribut | Persepsi Merek Susu Kental | ||||
| Merek A | Merek B | Merek C | Merek D | Merek E | |
| Rasa | 6 | 7 | 6 | 6 | 7 |
| Aroma | 5 | 7 | 6 | 6 | 7 |
| Kekentalan | 6 | 6 | 6 | 6 | 6 |
| Harga | 7 | 6 | 6 | 6 | 7 |
Langkah-langkah Analisis
- Ketik data Tabel 1 di dalam SPSS. Di SPSS, penulisan nama merek harus diberi tanda slash. Merek A ditulis sebagai Merek_A.
- Lakukan proses berikut: Analyze>Scale>Multidimension Scaling>Proxscall.
- Pada jendela dialog yang muncul pilih ‘Create proximities from data‘ dan ‘One matrix source‘.
- Highlight dan drag semua merek ke dalam sel Variables.
- Pastikan meminta Common space, Common Space Coordinated, Distances, dan Multiple stress measures.
- Execute.
Hasil dan Interpretasinya
Tabel output pertama SPSS memberikan informasi berikut.
Ringkasan
| Case Processing Summary | ||
| Cases | 5 | |
| Sources | 1 | |
| Objects | 5 | |
| Proximities | Total Proximities | 10a |
| Missing Proximities | 0 | |
| Active Proximitiesb | 10 | |
Tabel ini menginformasikan bahwa jumlah objek (merek) yang diolah adalah lima, sumbernya satu matriks (responden) dan proximity atau jarak (distance) yang dihasilkan ada 10. Rinciannya dapat dilihat pada tabel distance di bawah.
Goodness-of-fit
Setiap pembentukan dalam ilmu statistika selalu disertai oleh pemeriksaan apakah model yang dihasilkan baik atau tidak. Tabel di bawah ini berisikan informasi yang diperlukan untuk menjawab kebutuhan dimaksud. Penjelasan tentang kriteria Goodness-of-fit MDS disajikan di sini. Yang kita butuhkan sesuai dengan data kita adalah Normalized Raw Stress (NRS) dan Dispersion Accounted For (D.A.F.). Nilai NRS=0.0009 dan DAF=0.99991 menunjukkan bahwa model kita adalah sempurna (perfect).
| Final Coordinates | ||
| Dimension | ||
| 1 | 2 | |
| Merek_A | .798 | .339 |
| Merek_B | -.650 | -.170 |
| Merek_C | .208 | -.309 |
| Merek_D | .208 | -.309 |
| Merek_E | -.564 | .448 |
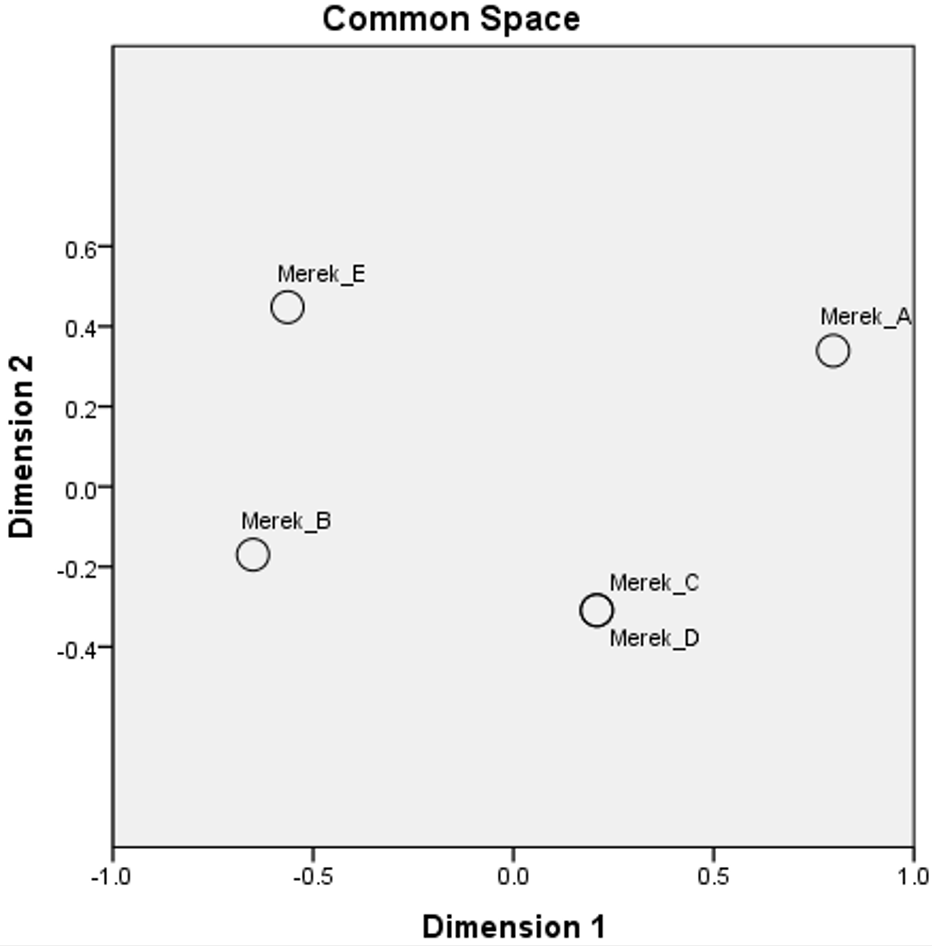
Peceptual map diberikan dalam bentuk koordinat dan gambar (common space). Tampak bahwa merek C dan D memiliki titik yang sama karena memang pada tabel data di atas, data keduanya sama persis.
Distances
Tabel distances menyatakan jarak Euclidean, yaitu jarak geometri antar merek. Jarak ini tidak memiliki satuan panjang dan hanya dipakai untuk menilai secara kesamaan dan ketidaksamaan merek secara relatif. Semakin tinggi angka berarti jarak semakin jauh dan merek semakin tidak sama. Terlihat pada tabel bahwa jarak antara Merek C dan D adalah 0.000, yang berarti kedua merek tidak memiliki jarak, sehingga memiliki satu posisi seperti pada perceptual map di atas. Jarak terjauh adalah antara Merek A dan merek B. Berarti kedua merek inilah yang paling tidak sama.
| Distances | |||||
| Merek_A | Merek_B | Merek_C | Merek_D | Merek_E | |
| Merek_A | .000 | ||||
| Merek_B | 1.535 | .000 | |||
| Merek_C | .876 | .869 | .000 | ||
| Merek_D | .876 | .869 | .000 | .000 | |
| Merek_E | 1.367 | .624 | 1.081 | 1.081 | .000 |
Reminder
Proses MDS yang ditampilkan di sini dilakukan untuk data seorang responden saja (one matrix source). Pertanyaan, bagaimana kalau responden banyak? Kita tidak bisa melakukan MDS sekaligus untuk semua responden, tetapi satu-satu. Kemudian, titik koordinat merek, yang dihasilkan MDS dari setiap responden dirata-ratakan. Kemudian, dengan koordinat rata-rata itulah dibuat peta persepsi.