Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Pendahuluan
Sebagai dependence technic, analisis diskriminan sama regresi linier berganda (multivariabel regression), namun berbeda tujuan. Analisis diskriminan merupakan teknik yang akurat dalam memprediksi termasuk dalam kategori apa seseorang, dengan catatan data-data yang dilibatkan terjamin keakuratannya. Dengan teknik ini, sebuah perusahaan asuransi, misalnya, dapat memprediksi apakah seorang nasabah baru akan bertahan terus sesuai dengan program ataukah berhenti membayar polis di tengah jalan. Tentu dengan catatan model diskriminan yang dipakai akurat. Dengan teknik ini sebuah perusahaan juga dapat memprediksi apakah seorang karyawan baru akan memiliki produktivitas yang tinggi atau tidak.
Dalam analisis diskriminan variabel dependen adalah bersifat kategoris (menggunakan skala ordinal ataupun nominal) dan variabel independent menggunakan skala metrik (interval dan rasio). Sama seperti regresi berganda, dalam analisis diskriminan, variabel dependen hanya satu, sedangkan variabel independent dua atau lebih (multiple). Misalnya, variabel dependen adalah pilihan merek mobil: Avanza, Xpander, Ertiga dan Xenia. Variabel independen adalah rating setiap merek pada sejumlah atribut (misalnya: konsumsi bahan bakar, tenaga mesin, eksterior, interior, harga jual kembali, spare-part, dan lain-lain), dengan skala numerik (internal atau rasio).
Dalam analisis diskriminan, variabel dependen dapat berupa variabel dua kategori (misalnya: nasabah bertahan, nasabah keluar di tengah jalan). Teknik demikian dinamakan two-group discriminant analysis. Seringkali variabel dependen lebih dari dua kategori (misalnya, sangat loyal, cukup loyal, tidak loyal). Teknik ini dinamakan multiple discriminant analysis.
Pendahuluan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Model Analisis Diskriminan
Model analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai variabel independent. Model dasar analisis diskriminan mirip dengan regresi berganda. Bedanya, kalau variabel dependen regresi berganda dilambangkan dengan Y, maka dalam analisis diskriminan dilambangkan dengan D, yaitu:
D=b0+b1X1 + b2X2 + … bkXk
Di mana, D= skor diskriminan, bo = konstanda, bi= koefisien diskriminan atatu bobot, dan Xk= prediktor atau variabel independent.
Dalam analisis diskriminan yang diestimasi adalah koefisien ‘b’, sehingga nilai ‘D’ setiap grup sedapat mungkin berbeda, yang terjadi saat rasio jumlah kuadrat antar grup (between-group sum of squares) terhadap jumlah kuadrat dalam grup (within-group sum of squares) untuk skor diskriminan setiap objek atau subjek, mencapai maksimum. Berdasarkan nilai D itulah keanggotaan suatu objek atau subjek diprediksi.
Pendahuluan | Model Analisis Diskriminan | Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Istilah-istilah yang Digunakan
Sebelum membicarakan analisis diskriminan lebih jauh, ada baiknya kita membiasakan diri dengan koefisien-koefisien statistik yang dipakai untuk berbagai keperluan.
- Korelasi kanonikal (canonical correlation), mengukur tingkat asosiasi antara skor diskriminan dengan grup. Koefisien ini merupakan ukuran hubungan fungsi diskriminan tunggal dengan sejumlah variabel dummy yang menyatakan keanggotaan grup.
- Centroid, adalah nilai rata-rata (mean) skor diskriminan untuk grup tertentu. Banyaknya centroid sama dengan banyaknya grup. Setiap centroid mewakili satu grup. Rata-rata untuk sebuah grup berdasarkan semua fungsi disebut group centroids.
- Cutting score adalah nilai rata-rata centroid yang dapat dipakai sebagai patokan mengelompokkan objek. Misalnya, kalau dalam analisis diskriminan dua grup cutting score adalah 0.15, maka keanggotaan suatu objek dapat dilihat apakah skor diskriminan objek tersebut di bawah ataukah di atas cutting score.
- Discriminant loadings (disebut juga structure correlations) merupakan korelasi linier sederhana antara setiap variabel independen dengan skor diskriminan untuk setiap fungsi diskriminan.
- Hit ratio merupakan nilai yang dapat menjawab: “Berapa persen objek yang dapat diklasifikasi secara tepat dari jumlah total objek”? Hit ratio merupakan salah satu kriteria untuk menilai kekuatan persamaan diskriminan dalam mengelompokkan objek.
- Matrik klasifikasi (classification matrix). Sering juga disebut confusion atau prediction matrix. Matrik klasifikasi berisikan jumlah kasus yang diklasifikasikan secara tepat dan yang diklasifikasikan secara salah (misclassified). Kasus yang diklassifikasi secara tepat muncul dalam diagonal matrik, tempat di mana grup prediksi (predicted group) dan grup sebenarnya (actual group) sama.
- Koefisien fungsi diskriminan (discriminant coefficient function). Koefisien fungsi diskriminan (tidak distandarisasi) adalah pengali (multipliers) variabel, di mana variabel adalah dalam nilai asli pengukuran.
- Skor diskriminan (discriminant score). Koefisien yang tidak distandarisasi (unstandardized score) dikalikan dengan nilai-nilai variabel.
- Eigenvalue. Untuk setiap fungsi diskriminan, eigenvalue adalah rasio antara jumlah kuadrat antar kelompok (sums of squares between group) dengan jumlah kuadrat dalam kelompok (sums of squares within group). Eigenvalue yang besar menunjukkan fungsi yang semakin baik.
- Nilai F dan signifikansinya. Nilai F dihitung melalui ANOVA satu arah, di mana variabel-variabel yang dipakai untuk mengelompokkan (grouping variable) berlaku sebagai variabel independen kategoris (categorical independent variable). Sedangkan setiap prediktor, diperlakukan sebagai variabel metrik.
- Rata-rata grup dan standar deviasi grup. Rata-rata grup dan standar deviasi grup dihitung untuk setiap grup.
- Pooled-with correlation matrix, menyatakan korelasi antar variabel independen, yang dihitung dengan mencari rata-rata matrik covarians tersendiri untuk semua grup.
- Koefisien fungsi diskriminan terstandarisasi (standardized discriminant functions coefficient), merupakan koefisien fungsi diskriminan yang dipakai sebagai pengali (multipliers) pada saat variabel telah distandarisasi dengan menjadikan rata-rata 0 dan standar deviasi 1.
- Korelasi struktur (structure correlations), yang juga disebut discriminant loadings, merupakan korelasi yang merepresentasikan korelasi sederhana (simple correlation) antara prediktor-prediktor dan fungsi diskriminan.
- Matrik korelasi total (total correlation matrix). Diperoleh kalau setiap kasus (objek penelitian) dianggap berasal dari satu sampel (single sampel) dan korelasi dihitung. Dengan begitu, matrik korelasi total dapat diperoleh.
- Wilks’ λ. Kadang-kadang juga disebut statistic U. Untuk setiap prediktor, Wilks’ λ adalah rasio antara antara jumlah kuadrat dalam kelompok (within-group sums of squares) dan jumlah kuadrat total (total sums of squares). Nilainya berkisar antara 0 sampai 1. Nilai Lambda yang besar (mendekati 1) menunjukkan bahwa rata-rata group cenderung tidak berbeda. Sebaliknya, nilai Lambda yang kecil (mendekati 0), menunjukkan rata-rata grup berbeda.
Melakukan Analisis Diskriminan
Merujuk pada Malhotra (2006), analisis diskriminan terdiri dari lima tahap, yaitu: (1) merumuskan masalah, (2) mengestimasi koefisien fungsi diskriminan, (3) memastikan signifikansi determinan, (4) menginter-pretasi hasil dan (5) menguji signifikansi analisis diskriminan.[i]
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Merumuskan Masalah
Tahap ini mencakup jawaban atas pertanyaan: “Kenapa analisis diskriminan dilakukan (latarbelakang masalah) dan apa tujuan analisis diskriminan, termasuk variabel-variabel apa yang dilibatkan? Kalau analisis diskriminan dipakai sebagai alat analisis dalam sebuah penelitian formal (skripsi dan thesis), tahap pertama, kedua dan ketiga dijelaskan pada metodologi penelitian.
Saat ini analisis diskriminan sangat mudah dilakukan karena banyaknya software pendukung. Namun, karena software akan melakukan tugasnya begitu data dimasukkan, perlu dipastikan terlebih dahulu bahwa instrumen yang digunakan akurat (baik secara teori maupun statistik) dan datanya reliabel. Sebab, pameo “Garbage in garbage out”, belaku juga untuk analisis diskriminan.
Pada tahap ini peneliti juga mengidentifikasi sasaran, variabel dependen (disebut juga criterion variable), serta variabel independen. Variabel dependen harus berisikan dua atau lebih kategori, di mana antara satu kategori dengan kategori lain bersifat terpisah (mutually exclusive). Sekiranya variabel dependen memakai skala metrik (interval ataupun rasio), skala variabel dependen tersebut harus dirubah menjadi kategori terlebih dahulu. Misalnya, sikap yang kita ukur dengan skala numeric berskala 1 sampai tujuh, dapat dirubah menjadi dua kategori (comfortable dan uncomfortable) atau tiga kategori (comfortable, neutral dan uncomfortable) atau lainnya.
Jangan terlalu kaku dalam menetapkan batas antar kategori, sebab kita harus melihat proposi setiap kategori. Kalau tidak proporsional, misalnya satu kategori berisikan 98% sedangkan kategori lain hanya 2% dari total objek, maka batas kategori (cut-off) dapat digeser, sampai ditemukan jumlah objek yang proporsional pada setiap kategori yang dibentuk. Pemilihan variabel prediktor pun harus didasarkan pada teori ataupun riset sebelumnya.
Tahap selanjutnya adalah membagi sampel ke dalam dua bagian. Satu bagian berfungsi sebagai sampel estimasi atau sampel analisis. Sesuai dengan namanya, sampel ini dipakai untuk mengestimasi fungsi diskriminan.
Satu bagian lagi disebut holdout atau sampel validasi (validation sampel), disimpan untuk mem-validasi fungsi diskri-minan. Kalau jumlah sampel besar, maka sampel dapat dibagi dua, setengahnya sebagai sampel analisis, setengahnya lagi sampel validasi.
Ada baiknya memperhatikan distribusi dalam sampel total. Seandainya sampel total berisikan 30% responden yang loyal dan 70% responden yang tidak loyal, maka setelah pembagian, diharapkan ditemukan pula distribusi yang sama pada sampel analisis (30% responden loyal dan 70% responden tidak loyal) dan sampel validasi (30% responden loyal dan 70% responden tidak loyal.
Validasi fungsi diskriminan perlu dilakukan berulang-ulang. Setiap kali, sampel perlu di-split ke dalam bagian analisis dan validasi. Fungsi diskriminan perlu diestimasi, kemudian validasi dilakukan. Jadi, keakuratan fungsi didasarkan pada sejumlah percobaan.
Contohnya, kita ingin kita ingin mempelajari faktor-faktor apa yang mempengaruhi para dosen dalam memilih jalur penelitian dalam sebuah perguruan tinggi: lewat lembaga Litbang dan penelitian sendiri. Ukuran sampel 50 orang. Dari jumlah itu, sebanyak 30 dosen dijadikan sampel analisis (Tabel 1). Sisanya, 20 dosen, dijadikan sebagai sampel validasi. Para dosen yang memakai dana Litbang diberi kode 1 dan yang memakai dana sendiri diberi kode 2. Distribusi kedua bagian dalam hal penelitian sendiri dan penelitian lewat Litbang, pada kedua sampel dapat dikatakan berimbang.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Mengestimasi Fungsi Diskriminan
Estimasi dapat dilakukan setelah sampel analisis diperoleh. Ada dua pendekatan umum yang tersedia. Pertama, metoda langsung (direct method), yaitu suatu cara mengestimasi fungsi diskriminan dengan melibatkan variabel-variabel prediktor sekaligus. Setiap variabel dimasukkan tanpa memperhatikan kekuatan diskriminan masing-masing variabel. Metoda ini baik kalau variabel-variabel prediktor dapat diterima secara teoritis.
Kedua, stepwise method. Dalam metoda ini, variabel prediktor dimasukkan secara bertahap, tergantung pada kemampuannya melakukan diskriminasi grup. Metoda ini cocok kalau peneliti ingin memilih sejumlah variabel prediktor untuk membentuk fungsi diskriminan.
Contoh soal. Dosen-dosen Universitas Internasional, sebuah perguruan tinggi swasta, diwajibkan untuk melakukan penelitian (riset) ilmiah minimal sekali setahun. Untuk membantu dosen-dosen melakukan riset, perguruan tinggi itu menyediakan dana yang dapat diperoleh setelah proposal penelitian para dosen dianggap layak oleh lembaga penelitian dan pengembangan (litbang) perguruan tinggi itu. Para dosen yang merasa mampu juga dapat melakukan penelitian tanpa harus melalui lembaga litbang.
Ternyata, sekalipun Universitas Internasional menyediakan dana penelitian, lebih banyak dosen yang melakukan penelitian dengan biaya sendiri.
Untuk mengetahui penyebab kenyataan ini, dilakukan penelitian terhadap 50 dosen yang melakukan penelitian, 24 di antaranya lewat litbang, 26 menggunakan biaya sendiri. Empat variabel yang dijadikan sebagai variabel independen adalah gaji (X1), sikap terhadap litbang (X2), kemampuan melakukan riset (X3), dan daya tarik topik (attractiveness) yang diteliti (X4).
Untuk pembelajaran, kita gunakan angka 1 (satu) mewakili penelitian lewat litbang dan angka 2 (dua) untuk penelitian yang dibiaya sendiri. Apakah harus angka 1 dan 2? Tidak juga. Angka berapa pun boleh, misalnya 1 dan 3 atau 3 dan 6. Angka tersebut dipakai SPSS hanya sebagai perlambang. Namun, ada baiknya di dalam SPSS, kolom value variabel ‘jalur’ dirinci, seperti pada contoh data di bawah ini.
Sampel dibagi dua secara acak. Hasilnya dibandingkan dengan harapan bahwa hasil yang diberikan kedua sampel sama. Dalam penelitian ini ada 50 responden. Sebanyak 30 responden dipakai sebagai sampel analisis (Tabel 1), yang bisa di-download dari sini. Sisanya, 20 responden, dijadikan sebagai sampel holdout (Tabel 2). Datanya ada di sini.
Tabel 1. Sampel Utama
| Reponden | Jalur Pilihan | X1 | X2 | X3 | X4 |
| 1 | 1 | 3.2 | 5 | 6 | 7 |
| 2 | 1 | 4 | 6 | 5 | 5 |
| 3 | 1 | 5.2 | 5 | 5 | 5 |
| 4 | 1 | 4 | 7 | 6 | 5 |
| 5 | 1 | 2.7 | 6 | 5 | 6 |
| 6 | 1 | 3.5 | 5 | 7 | 6 |
| 7 | 1 | 4 | 6 | 5 | 7 |
| 8 | 1 | 5 | 6 | 7 | 6 |
| 9 | 1 | 4 | 5 | 7 | 6 |
| 10 | 1 | 3.1 | 5 | 6 | 5 |
| 11 | 1 | 3.7 | 6 | 7 | 6 |
| 12 | 1 | 4.4 | 6 | 6 | 5 |
| 13 | 1 | 3.6 | 7 | 7 | 7 |
| 14 | 1 | 4 | 6 | 6 | 7 |
| 15 | 2 | 5 | 5 | 6 | 4 |
| 16 | 2 | 5.2 | 4 | 5 | 4 |
| 17 | 2 | 6 | 5 | 4 | 5 |
| 18 | 2 | 4 | 5 | 5 | 4 |
| 19 | 2 | 4.7 | 5 | 4 | 5 |
| 20 | 2 | 4.8 | 4 | 4 | 4 |
| 21 | 2 | 6.1 | 3 | 3 | 5 |
| 22 | 2 | 3 | 3 | 4 | 5 |
| 23 | 2 | 5 | 4 | 5 | 5 |
| 24 | 2 | 4 | 4 | 4 | 5 |
| 25 | 2 | 6 | 3 | 4 | 4 |
| 26 | 2 | 7 | 2 | 4 | 4 |
| 27 | 2 | 5.6 | 5 | 4 | 4 |
| 28 | 2 | 5.2 | 4 | 3 | 4 |
| 29 | 2 | 3.4 | 4 | 5 | 5 |
| 30 | 2 | 4.7 | 5 | 4 | 5 |
Tabel 2. Sampel Holdout
| Responden | Jalur Pilihan | X1 | X2 | X3 | X4 |
| 1 | 1 | 3.1 | 6 | 6 | 7 |
| 2 | 1 | 4.3 | 6 | 6 | 5 |
| 3 | 1 | 5.1 | 6 | 5 | 5 |
| 4 | 1 | 4.5 | 6 | 7 | 5 |
| 5 | 1 | 3 | 6 | 6 | 6 |
| 6 | 1 | 4 | 5 | 7 | 6 |
| 7 | 1 | 4.2 | 7 | 5 | 7 |
| 8 | 1 | 5.1 | 6 | 7 | 7 |
| 9 | 1 | 3.6 | 5 | 6 | 6 |
| 10 | 1 | 4 | 6 | 6 | 5 |
| 11 | 2 | 4.7 | 4 | 3 | 4 |
| 12 | 2 | 5.7 | 4 | 3 | 5 |
| 13 | 2 | 4 | 4 | 4 | 5 |
| 14 | 2 | 5.1 | 5 | 5 | 5 |
| 15 | 2 | 4.2 | 5 | 4 | 5 |
| 16 | 2 | 4.7 | 4 | 4 | 4 |
| 17 | 2 | 6 | 3 | 4 | 4 |
| 18 | 2 | 5 | 4 | 4 | 4 |
| 19 | 2 | 5 | 4 | 3 | 4 |
| 20 | 2 | 4.2 | 5 | 5 | 5 |
Langkah-langkah analisis
Langkah 1: Buka file SPSS sampel analisis.
Langkah 2: Prosedur: Analyze>Classify>Discriminant. Pada kotak dialog masukkan variabel ‘d’ sebagai gouping variables. Kemudian, klik define range. Lalu, pada kotak dialog kecil yang muncul, masukkan angka 1 pada sel minimum dan angka 2 pada sel maximum. Tampak di layar sebagai berikut:

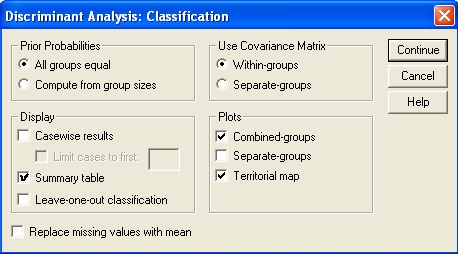
Langkah 3: Untuk kembali pada kotak dialog disriminant, pada kotak dialog Define range, klik Continue. Pada kotak dialog Discriminant analysis, klik Statistics, kemudian, pada kotak dialog Statistics, tandai sel Means, Univariate ANOVA, Box.s M, Unstandardized dan Within-goups correlations. Lalu, klik Continue.

Langkah 4: Klik Classify, lalu tandai pilihan-pilihan di bawah ini.

Langkah 5. Dari kotak dialog Discriminant analysis, klik Save, kemudian pada kotak dialog save yang muncul sesudahnya, pilih fasilitas-fasilitas seperti ditandai di bawah ini. Dengan fasilitas-fasilitas tersebut, SPSS akan memprediksi keanggotaan setiap responden, skor diskriminan responden, serta peluang keanggotaan responden pada grup 1 dan grup 2.

Interpretasi Output
Hasil analisis diskriminan dimulai dengan analisis deskriptif.. Pada Output 1, dari statistik grup (group statistics) secara kualitatif terlihat bahwa beda rata-rata variabel setiap grup dan rata-rata total. Rata-rata ini, kalau antar grup berbeda, mengindikasikan bahwa variabel-variabel di dalamnya berperan dalam mengelompokkan responden. Sekiranya rata-rata sebuah variabel sama pada kedua grup, bolehlah kita percaya bahwa variabel tersebut tidak berperan dalam mengelompokkan objek (atau responden).
| Group Statistics |
| Pilihan jalur penelitian | Mean | Std. Deviation | Valid N (listwise) |
| Unweighted | Weighted |
| 1.00 | Gaji | 3.8857 | .68259 | 14 | 14.000 |
| Kemampuan meneliti | 5.7857 | .69929 | 14 | 14.000 |
| Sikap penelitian | 6.0714 | .82874 | 14 | 14.000 |
| Kemenarikan topik | 5.9286 | .82874 | 14 | 14.000 |
| 2.00 | Gaji | 4.9813 | 1.04640 | 16 | 16.000 |
| Kemampuan meneliti | 4.0625 | .92871 | 16 | 16.000 |
| Sikap penelitian | 4.2500 | .77460 | 16 | 16.000 |
| Kemenarikan topik | 4.5000 | .51640 | 16 | 16.000 |
| Total | Gaji | 4.4700 | 1.04127 | 30 | 30.000 |
| Kemampuan meneliti | 4.8667 | 1.19578 | 30 | 30.000 |
| Sikap penelitian | 5.1000 | 1.21343 | 30 | 30.000 |
| Kemenarikan topik | 5.1667 | .98553 | 30 | 30.000 |
Standar deviasi juga mengindikasikan apakah sebuah variabel berperan baik sebagai diskriminator ataukah tidak. Peran tersebut baik kalau standar deviasi dalam grup lebih rendah dari standar deviasi total, sebab dalam grup tentu nilai-nilai variabel lebih homogen. Pada Output 1, semua variabel memenuhi syarat ini, kecuali variabel gaji, di mana standar deviasi gaji (variabel X1) grup 2 (Sdev=1.04640 ) lebih tinggi dibanding standar deviasi totalnya (Sdev=1.04127). Memang, seperti dijelaskan nanti, pengaruh variabel ini pada perbedaan jalur pilihan peneliti adalah paling rendah.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan | Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Tests of Equality of Group Means
Tests of Equality of Group Means memeriksa apakah setiap variabel independen menjalankan fungsi diskriminasi. Pada tabel di bawah ini, dengan α=0,05, maka nilai signifikansi nilai F menunjukkan bahwa ketika diperiksa secara sendiri-sendiri, semua variabel prediktor signifikan (karena nilai signifikansinya di bawah α=0,05).
| Tests of Equality of Group Means |
| Wilks’ Lambda | F | df1 | df2 | Sig. |
| Gaji | .715 | 11.161 | 1 | 28 | .002 |
| Kemampuan meneliti | .465 | 32.176 | 1 | 28 | .000 |
| Sikap penelitian | .420 | 38.687 | 1 | 28 | .000 |
| Kemenarikan topik | .459 | 33.002 | 1 | 28 | .000 |
Hipothesis yang diuji adalah:
H0: Rata-rata variabel ke-i pada kedua grup diskriminan yang terbentuk adalah sama.
Ha: Rata-rata variabel ke-i pada kedua grup diskriminan yang terbentuk adalah tidak sama.
Dengan nilai sig. semua variabel di bawah 0.05, punya cukup bukti untuk menolak H0 dan menyatakan bahwa memang rata-rata variabel pada kedua grup diskriminan yang terbentuk adalah berbeda.
Karena hanya dua grup yang dibentuk, maka fungsi diskriminan hanya ada satu, dengan eigenvalue sebesar 2,993, yang sudah mencakup 100 % varians yang dijelaskan (explained variance).
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means | Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Pooled within-groups correlation matrix
Analisis diskriminan mengharapkan korelasi yang rendah antar prediktor. Kita mengambil kesimpulan secara kualitatif. Pooled within-groups correlation matrix mengindikasikan korelasi yang rendah antar prediktor, sehingga, multikolinearitas dapat diabaikan.
| Pooled Within-Groups Matrices |
| Gaji | Kemampuan meneliti | Sikap penelitian | Kemenarikan topik |
| Correlation | Gaji | 1.000 | -.184 | -.180 | -.291 |
| Kemampuan meneliti | -.184 | 1.000 | .213 | .081 |
| Sikap penelitian | -.180 | .213 | 1.000 | .070 |
| Kemenarikan topik | -.291 | .081 | .070 | 1.000 |
Pada tabel di atas terlihat bahwa nilai korelasi tertinggi terjadi antara gaji dan kemenarikan topik dengan nilai absoulut 0.291. Kalau kita tetapkan r>0.70 sebagai batas nilai korelasi tinggi, korelasi antar variabel variabel adalah rendah (r<0.70) dan bisa diabaikan. Jadi, model diskriminan kita bebas dari multikolinearitas.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix | Tingkat Kepentingan Prediktor | Cutting Score | Hit Ratio
Box’s M Test of Equality
Apakah kedua grup berasal dari populasi yang sama? Syaratnya memang demikian. Untuk menjawabnya, perlu dipastikan bahwa matrik covariance kedua grup sama. Untuk membuktikannya, digunakan Statistik Box’s M. Statistik ini menguji hipothesis:
Ho: Matrik covariance kedua grup sama, artinya kedua grup berasal dari populasi yang sama
Ha: Matrik covariance kedua grup tidak sama, artinya kedua grup tidak berasal dari populasi yang sam
Box’s M Test of Equality of Covariance Matrices
| Box’s M | 10.892 |
| F | Approx. | .918 |
| df1 | 10 |
| df2 | 3581.580 |
| Sig. | .515 |
| Tests null hypothesis of equal population covariance matrices. |
Untuk contoh ini, nilai Box’s M adalah 10.892 dengan nilai sig.=0.515. Dengan demikian, pada α=0.05, tidak cukup bukti menolak Ho. Jadi, matrik kovarian kedua grup adalah sama. Dengan demikian, berdasarkan Box’s M, analisis diskriminan layak dilakukan.
Korelasi kanonikal adalah 0,866. Koefisien determinan (r2) diperoleh dengan memangkat-duakan korelasi kanonikal: (0,866)2=0,750. Angka ini mengindikasikan bahwa 75% varian variabel dependen dapat dijelaskan oleh variabel-variabel independen.
| Eigenvalues |
| Function | Eigenvalue | % of Variance | Cumulative % | Canonical Correlation |
| 1 | 2.993a | 100.0 | 100.0 | .866 |
| a. First 1 canonical discriminant functions were used in the analysis. |
Eigenvalue yang tinggi (lebih dari 1.00) menyatakan jumlah kuadrat antar kelompok atau sums of squares between group (SSbetween) lebih tinggi dibanding jumlah kuadrat dalam kelompok atau sums of squares within group (SSwithin). Perlu diketahui, SSwithin dihitung berdasarkan selisih antara skor setiap unit analisis dengan skor rata-dalam grup. SSbetween dihitung berdasarkan selisih antara skor setiap unit analisis dalam grup dengan rata-rata skor rata-rata semua unit analisis. Contoh perhitungan bisa dilihat di sini.
Uji Signifikansi
Tak ada gunanya mengintepretasi hasil analisis diskriminan kalau fungsinya tidak signifikan. Yang dimaksud signifikan adalah mampu melakukan fungsi diskriminasi dengan nyata. Hipothesis yang mau diuji adalah:
H0: Rata-rata semua variabel dalam semua grup (dalam contoh ini dua grup) adalah sama.
Ha: Rata-rata semua variabel dalam semua grup (dalam contoh ini dua grup) adalah berbeda.
Dalam SPSS, uji dilakukan dengan menggunakan Wilks’ λ. Kalau beberapa fungsi diuji sekaligus, sebagaimana dilakukan pada analisis diskriminan, statistik Wilks’ λ adalah hasil λ univariat untuk setiap fungsi.
| Wilks’ Lambda |
| Test of Function(s) | Wilks’ Lambda | Chi-square | df | Sig. |
| 1 | .250 | 36.001 | 4 | .000 |
Nilai Wilk’s lambda ditransformasi menjadi nilai chi-square. Pada hasil Output 4 terlihat bahwa Wilks’ λ berasosiasi sebesar 0,250 dengan fungsi diskriminan. Angka ini kemudian ditransformasi menjadi chi-quare dengan derajat kebebasan (ditulis df, singkatan dari degree of freedom) sebesar 4. Nilai chi-square adalah dengan nilai 36,001. Kesimpulannya, cukup bukti untuk menolak H0 dengan nilai sig.=0,000. Jadi, setelah analisis diskriminan dilakukan, rata-rata semua variabel dalam semua grup (dalam contoh ini dua grup) adalah berbeda. Dengan demikian kita dapat menyimpulkan bahwa fungsi memiliki kemampuan melakukan diskriminasi.
Sama-sama menggunakan nilai Wilks’ Lambda. Apa beda uji signifikansi dengan Test of Equality of Group Means? Uji signifikasi adalah uji kelayakan model. Test of Equality of Group Means adalah uji kelayakan variabel.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Cutting Score | Hit Ratio
Tingkat kepentingan prediktor
Untuk menjawab pertanyaan: “Variabel independen (disebut juga ‘variabel prediktor’ atau ‘prediktor’ saja) mana saja yang paling berperan (berkontribusi) dalam melakukan diskriminasi?” Pertama lihat “standardized coefficient”. Secara relatif, prediktor yang memiliki ‘standardized coeficient’ yang lebih besar menyumbangkan kekuatan diskriminasi (discriminating power) yang lebih besar terhadap fungsi, dibanding prediktor yang memiliki standardized coefficient lebih kecil. Jadi, seperti terlihat pada Output 5, dengan skor 0,545, prediktor ‘daya tarik topik’, memiliki tingkat kepentingan paling tinggi. Dengan skor -0,026 prediktor gaji memiliki peran yang paling kecil.
| Standardized Canonical Discriminant Function Coefficients |
| Function |
| 1 |
| Gaji | -.026 |
| Kemampuan meneliti | .456 |
| Sikap penelitian | .539 |
| Kemenarikan topik | .545 |
Kedua, peneliti juga bisa menggunakan structure matrix, yang juga disebut canonical loadings dan discriminant loadings. Jangan perhatikan negatif atau positifnya. Perhatikan nilai mutlaknya. Pada Output 6, dengan structure matrix, kita dapat menyimpulkan bahwa peran diskriminasi dari yang tertinggi sampai terendah adalah kemampuan peneliti, daya tarik topik, sikap terhadap litbang dan gaji dosen.
| Structure Matrix |
| Function |
| 1 |
| Sikap penelitian | .679 |
| Kemenarikan topik | .627 |
| Kemampuan meneliti | .620 |
| Gaji | -.365 |
| Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions. Variables ordered by absolute size of correlation within function. |
Cara ketiga, kita dapat menggunakan nilai F setiap prediktor, yang disebut univariate F ratio. Semakin besar nilai F, kontribusi terhadap diskriminasi semakin tinggi.
Nah, sekarang kita bandingkan tingkat kepentingan prediktor berdasarkan ketiga kriteria di atas, seperti pada tabel di bawah. Kesimpulan kita memang bisa berbeda, tergantung dari mana kita melihatnya. Disarankan, peneliti cukup menggunakan satu kriteria saja agar kesimpulan yang berbeda dapat dihindarkan.
| Variabel | Standardized Coefficient | Discriminant Loadings | Univariate F Ratio |
| Nilai | Ranking | Nilai | Ranking | Nilai | Ranking |
| X1 | -0.02557 | 4 | -0,365 | 4 | 11.16123 | 4 |
| X2 | 0.455568 | 3 | 0,620 | 3 | 32.1756 | 3 |
| X3 | 0.539336 | 2 | 0,679 | 1 | 38.68685 | 1 |
| X4 | 0.545003 | 1 | 0,627 | 2 | 33.00184 | 2 |
Dengan menggunakan ‘canonical discriminant function coefficients, kita dapat membentuk fungsi diskriminan, yaitu:
D = -10.125 – 0,029X1+ 0,674X2 + 0,549X3+0,802X4
Sebetulnya, koefisien di atas merupakan penyederhanaan dengan memberikan angka tiga desimal di belakang koma, seperti dihasilkan oleh program SPSS. Kalau output SPSS kita impor dengan program Excel, maka angka di belakang koma nilai koefisien lebih banyak, sehingga dengan memakai angka demikian, perhitungan skor diskriminan secara manual lebih presisi. Cara mengimpor adalah dengan mengkopi tabel output SPSS itu, lalu membuka Excel, terus melakukan Paste pada file yang telah dibuka itu. Hasilnya, seperti pada Output 7.
Dengan program SPSS sebenarnya kita tidak perlu lagi menghitung skor diskriminan (disebut juga Z scores) karena sudah disediakan oleh SPSS. Akan tetapi, untuk meningkatkan pemahaman, kita perlu mengetahui dari mana datangnya skor-skor itu. Persamaan di bawah ini, yang menggunakan koefisien dari Output 7, dapat dipakai menghitung skor diskriminan dengan presisi tinggi karena angkanya enam di belakang koma.
D=-10.124622 – 0,028541X1 + 0,674008X2 +0,5488X3 + 0,802052X4
Sekiranya kita menggunakan skor diskriminan yang telah diberikan oleh program komputer, maka persamaan pertama tidak bermasalah. Persamaan ini baru bermasalah kalau kita menghitung skor diskriminan secara manual, sebab angkanya bisa berbeda (walaupun tidak banyak) dengan skor diskriminan yang diberikan komputer. Lihat pengerjaan manual di bawah ini.
Canonical Discriminant Function Coefficient dengan Enam Angka di Belakang Koma.
| Canonical Discriminant Function Coefficients |
| Function |
| 1 |
| Gaji (X1) | -0.028541 |
| Kemampuan meneliti (X2) | 0.548800 |
| Sikap terhadap penelitian (X3) | 0.674008 |
| Daya tarik topik (X4) | 0.802052 |
| (Constant) | -10.124622 |
| Unstandardized coefficients |
Sumber: Output SPSS
Dengan persamaan kedua, untuk responden pertama, skor diskriminan adalah:
D=-10.124622 – 0,028541(3.2) + 0,5488(5) + 0,674008(6) +0,802052(7) = 2,18646
Sedangkan dengan persamaan pertama, skor diskriminan adalah:
D=-10.126-0,029(3.2)+0,674(5)+0.549(6)+0.802(7)=2.3708
Hasilnya berbeda, bukan? Memang, dengan persamaan pertamalah diperoleh semua skor pada Tabel 6,1.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Hit Ratio
Cutting Score
Sebelum analisis diskriminan dilakukan, kita hanya mempunyai dua skor berdasarkan jalur yang dipilih, yaitu 1 dan 2. Angka 1 menyatakan penelitian yang dibiayai Litbang, angka 2 menyatakan penelitian atas biaya sendiri. Skor diskriminan yang kita cari dapat dipakai untuk memprediksi jalur setiap responden, apakah golongan 1 atau 2. Misalnya, dengan skor diskriminan sebesar 2,18646, dapatkah kita prediksi masuk mana responden 1? Jawabannya dapat.
Untuk memprediksi responden mana masuk golongan mana, kita dapat menggunakan optimum cutting score. Memang dari komputer, informasi ini sudah diperoleh. Akan tetapi, tak ada salahnya kalau kita mengetahui cara mengerjakannya secara manual.
Rumus yang digunakan berbeda untuk grup yang proporsional (kedua grup mempunyai jumlah anggota yang sama) dan yang tidak proporsional (jumlah anggota kedua grup berbeda).
Untuk dua grup yang mempunyai ukuran yang sama cutting score dinyatakan oleh rumus:

Jadi, pembatasnya adalah 0,000. Kalau di atas 0,000 masuk grup 1 dan kalau di bawah 0,000 masuk grup 2. Oleh karena itu, responden 1 pada sampel holdout, dengan skor diskriminan 2,28368. Responden 11, dengan skor diskriminan -3,15108, masuk grup 2. Dengan skor-skor yang ada, sekarang prediksilah setiap responden.
Apabila dua grup berbeda ukuran, seperti sampel analisis, maka rumus cutting score yang digunakan adalah:

Responden 1 sampel analisis diprediksi ke grup 1 skor diskrimi-nannya 2,18646. Responden 3 yang aslinya masuk grup 1, diprediksi masuk grup 2 karena skor diskriminannya di bawah cutting score, yaitu -0,14431. Ini namanya error atau misclassified.
Tanpa cutting score pun, sebenarnya kita dapat langsung memprediksi grup setiap responden, yaitu dengan melihat paling dekat ke centroid mana skor diskriminan masing-masing objek. Misalnya, skor diskriman responden 1 sampel analisis, yang nilainya 2.18646, tentunya lebih dekat ke 1.787 (centroid grup 1) daripada ke -1,564 (centroid grup 2). Oleh karena itu diprediksi masuk ke grup 1. Responden 15 sampel analisis, dengan skor diskriminan -0,27107, tentu lebih dekat ke -1,564 (centroid grup 2) dan masuk grup 2.
| Functions at Group Centroids |
| Pilihan jalur penelitian | Function |
| 1 |
| 1.00 | 1.787 |
| 2.00 | -1.564 |
Program SPSS juga memberikan output berupa peluang unit unit analisis masuk grup 1 dan grup 2. Ke grup mana peluang lebih besar, ke grup itulah unit analisis dimasukkan. Responden 1 sampel analisis, misalnya, memiliki peluang ke grup 1 sebesar 0,99904 dan ke grup 2 sebesar 0,00096. Tentunya, peluang ke grup 1 lebih besar, jadi ke grup itulah responden 1 bergabung.
Pendahuluan | Model Analisis Diskriminan | Istilah-istilah yang Digunakan |Merumuskan Masalah | Mengestimasi Fungsi Diskriminan |Test of Equality of Group Means |Pooled Within-Groups Correlation Matrix |Box’M Test of Equality | Tingkat Kepentingan Prediktor | Cutting Score
Hit ratio
Hit rasio adalah persentase kasus atau responden yang kelompoknya dapat dipreksi secara tepat. Kalau jumlah seluruh kasus sampel analisis (atau responden) adalah 30 (pada kedua grup), lalu fungsi diskiminan dapat memprediksi 29 kasus secara tepat (hanya responden 3 yang error), maka hit ratio adalah 29/30=96,67%. Tanpa menggunakan kriteria apa pun, karena mampu memprediksi grup keanggotaan 29 responden dari total 30 responden dan hanya satu yang salah prediksi, kita dapat menilai angka ini sangat bagus.
| Classification Resultsa |
| | Pilihan jalur penelitian | Predicted Group Membership | Total |
| | 1.00 | 2.00 |
| Original | Count | 1.00 | 13 | 1 | 14 |
| 2.00 | 0 | 16 | 16 |
| % | 1.00 | 92.9 | 7.1 | 100.0 |
| 2.00 | .0 | 100.0 | 100.0 |
| a. 96.7% of original grouped cases correctly classified. |
Working with Holdout Sample
Dalam uraian di atas, persamaan diskriminan yang kita miliki adalah signifikan dan akurat (akurasi 96.7%). Pertanyaannya, apakah persamaan ini berlaku untuk seluruh populasi saat ini maupun yang akan datang? Pertanyaan lain, kalau ada dosen baru yang masuk, dapatkah diprediksi yang bersangkutan akan memilih jalur mana?
Pertanyaan kedua di atas ini sangat penting bagi berbagai pihak. Bagi para praktisi SDM, persamaan diskriminan dapat digunakan untuk memprediksi, apakah seorang calon karyawan akan sukses ataupun gagal. Untuk menjawab pertanyaan ini diperlukan persamaan diskriminan yang akurat.
Kegunaan holdout sample adalah membuktikan akurasi persamaan diskriminan, yang diperoleh melalui sampel analisis. Apabila persamaan tersebut dapat memprediksi keanggotaan holdout sample dengan hit ratio tinggi, maka persamaan diskriminan dapatlah dianggap akurat.
Ini persamaan diskriminan kita, yang diperoleh dari sample analisis:
D = -10.125 – 0,029X1+ 0,674X2 + 0,549X3+0,802X4
Dengan persamaan tersebut, kita dapat menghitung skor diskriminan setiap responden dengan bantuan fasilitas Transform>Compute Variables pada SPSS. Bagi pembaca yang belum tahu caranya, disediakan video pembelajaran (sabar ya, sedang dibuat). Skor diskriminan hasil prediksi ditampilkan pada gambar tabel SPSS di bawah.
Setelah skor diskriminan diperoleh, dicari jaraknya dengan centroid grup 1 dan grup 2. Keanggotaan responden ditentukan berdasarkan nilai jarak ke centroid yang lebih kecil. Contohnya, respoden 1 diprediksi masuk grup 1 karena jarak grup 1 (1.03) lebih kecil dibanding ke grup 2 (4.38). Oh ya, jarak ditentukan berdasarkan nilai absolut selisih antara skor diskriminan dan centroid (caranya bisa dilihat pada video).

Seperti diperlihatkan pada tabel SPSS di atas, dengan membandingkan pilihan jalur aktual dan prediksi, fungsi diskriminan mampu memprediksi keanggotaan semua (100%) responden sample holdout. Hasil yang sama juga diperlihatkan pada tabel klasifikasi di bawah. Dengan hasil ini, dapat disimpulkan bahwa fungsi diskriminan memiliki akurasi tinggi.
| Tabel Klasifikasi Responden Sample Holdout |
| | Jalur Penelitian Aktual | Prediksi Jalur Penelitian | Total |
| | 1.00 | 2.00 |
| Original | Count | 1.00 | 10 | 0 | 10 |
| 2.00 | 0 | 10 | 10 |
| % | 1.00 | 100.0 | .0 | 100.0 |
| 2.00 | .0 | 100.0 | 100.0 |
| a. 100.0% of original grouped cases correctly classified. |
Batas Hit-Ratio yang Layak
Pertanyaannya, bagaimana kalau hit rasio tidak sebaik itu (misalnya 60%), apakah fungsi diskriminan akurat? Kalau ukuran setiap grup sama, lihat nilai kesempatan klasifikasi. Menurut Maholtra, kesempatan klasifikasi untuk grup berukuran sama adalah 1 dibagi jumlah grup. Untuk sampel yang terdiri dari 2 grup, maka kesempatan klasifikasi adalah ½ atau 0,50 (Malhotra, 2020).
Hair et al. (2016) menyatakan bahwa kriteria hit ratio yang baik adalah kalau sama atau melebihi kesempatan klasifikasi ditambah seperempatnya. Kalau kesempatan klasifikasi adalah 50%, maka batas minimal hit rasio adalah 0,50 + (0,25) (0,50)=0,625 atau 62,5%. Kalau kita memiliki 4 grup, maka kesempatan klasifikasi adalah 25%. Dengan cara yang sama, batas minimal hit ratio adalah 31,25%.
Untuk sampel holdout kriteria ini dapat digunakan. Sayangnya, dua grup dalam sampel analisis tidak sama ukurannya. Kriteria kesempatan proporsional (proportional chance ciriterion) dapat dipakai kalau ukuran grup-grup tidak sama dan kalau tujuan peneliti adalah menentukan secara tepat keanggotaan objek pada dua (atau lebih) grup. Rumusnya adalah:
CPRO=p2+(1-p2)
Di mana, p=proporsi responden pada grup 1 dan 1-p=proporsi responden pada grup 2. Untuk sampel analisis, proporsi grup 1 adalah 46,67% dan proporsi grup 2 adalah 53,33%. Dengan kedua proporsi ini, maka kita memperoleh CPRO=(0, 4667)2+(0,5333)2=0,5022=50,22.
Akurasi Statistik
Kita dapat menguji secara statistik apakah klasifikasi yang kita lakukan (dengan menggunakan fungsi diskriminan) akurat atau tidak. Uji statistik yang digunakan dinamakan Press’s Q Statistic. Ukuran sederhana ini membandingkan jumlah kasus yang diklasifikasi secara tepat dengan ukuran sampel dan jumlah grup. Nilai yang diperoleh dari perhitungan kemudian dibandingkan dengan nilai kritis (critical value) yang diambil dari tabel Chi-Square dengan derajat kebebasan satu (ditulis dk=1 atau df=1 atau v=1) dan tingkat keyakinan sesuai keinginan kita. Statistik Q ditulis dengan rumus:

Di mana, N= ukuran total sampel, n= jumlah kasus yang diklasifikasi secara tepat dan K = jumlah grup. Untuk sampel analisis, kita dapat menghitung:

Dengan α=0,05 dan df=1, nilai X2 tabel adalah 3,841. Dengan demikian, dapat kita simpulkan bahwa fungsi diskriminan kita akurat.
Multiple Discriminant Analysis
PADA analisis diskriminan ganda (multiple discriminant analysis), grup yang dimiliki tidak lagi dua, akan tetapi tiga, empat, atau lebih grup. Kalau diaplikasikan pada dua grup, maka persamaan diskriminan yang dibentuk hanya ada satu. Sedangkan kalau kita memiliki tiga atau lebih grup, maka persamaan diskriminan yang dibentuk adalah jumlah grup itu dikurang satu. Jadi, kalau grup ada tiga grup sebagai variabel dependen, maka persamaan diskriminan yang dibentuk adalah dua, kalau grup ada lima, persamaan diskriminan ada empat, demikian seterusnya … read more