Last updated on June 20, 2022 by Bilson Simamora
PADA analisis diskriminan ganda (multiple discriminant analysis), grup yang dimiliki tidak lagi dua, akan tetapi tiga, empat, atau lebih grup. Kalau diaplikasikan pada dua grup, maka persamaan diskriminan yang dibentuk hanya ada satu. Sedangkan kalau kita memiliki tiga atau lebih grup, maka persamaan diskriminan yang dibentuk adalah jumlah grup itu dikurang satu. Jadi, kalau grup ada tiga grup sebagai variabel dependen, maka persamaan diskriminan yang dibentuk adalah dua, kalau grup ada lima, persamaan diskriminan ada empat, demikian seterusnya.
Apa yang dilakukan pada analisis diskriminan berganda, sama saja dengan yang dilakukan pada analisis disriminan dua grup. Perbedaannya, selain jumlah fungsi diskriminan, juga menyangkut cara memprediksi grup sebuah kasus atau seorang responden.
Penjelasan selanjutnya tentang konsep ini dilakukan dengan memakai contoh berikut. Seorang peneliti tertarik untuk mengetahui faktor-faktor apa yang mempengaruhi pilihan orang untuk berlibur. Dia mengamati bahwa pada masa liburan anak sekolah, tujuan berlibur ada tiga, yaitu: (1) di dalam kota, (2) ke luar kota, (3) ke luar pulau. Variabel-variabel independen yang dipakai sebagai prediktor adalah pendapatan keluarga (X1), sikap tentang pentingnya liburan untuk anak (X2), sikap terhadap perjalanan (X3), jumlah anak (X4) rata-rata usia anak (X5) dan asal kepala keluarga (X6). Datanya dapat di-download dari sini. Ini datanya:
Tabel 1. Data yang Diolah
| Responden | X1 | X2 | X3 | X4 | X5 | X6 | Tujuan Berlibur |
| 1 | 47.1 | 2 | 5 | 3 | 14 | 1 | 1 |
| 2 | 69.1 | 7 | 6 | 3 | 12 | 2 | 3 |
| 3 | 42.3 | 3 | 3 | 2 | 11 | 1 | 1 |
| 4 | 57 | 8 | 3 | 2 | 7 | 2 | 2 |
| 5 | 75 | 8 | 7 | 4 | 15 | 3 | 3 |
| 6 | 43.2 | 2 | 5 | 2 | 16 | 2 | 2 |
| 7 | 56.2 | 1 | 8 | 4 | 14 | 1 | 2 |
| 8 | 37.3 | 2 | 7 | 4 | 14 | 2 | 1 |
| 9 | 49.3 | 4 | 2 | 3 | 15 | 3 | 3 |
| 10 | 32.1 | 5 | 4 | 3 | 16 | 2 | 1 |
| 11 | 37.5 | 3 | 2 | 3 | 11 | 1 | 1 |
| 12 | 70.3 | 6 | 7 | 4 | 19 | 2 | 3 |
| 13 | 35 | 6 | 4 | 4 | 17 | 3 | 1 |
| 14 | 57 | 2 | 4 | 5 | 14 | 2 | 2 |
| 15 | 50.4 | 5 | 2 | 3 | 6 | 1 | 2 |
| 16 | 38.3 | 6 | 6 | 2 | 14 | 2 | 1 |
| 17 | 62.9 | 7 | 5 | 3 | 18 | 3 | 3 |
| 18 | 71.9 | 5 | 8 | 4 | 20 | 2 | 3 |
| 19 | 48.5 | 7 | 5 | 4 | 6 | 1 | 1 |
| 20 | 52.7 | 6 | 6 | 4 | 15 | 3 | 3 |
| 21 | 46.2 | 5 | 3 | 3 | 21 | 3 | 2 |
| 22 | 64.1 | 7 | 5 | 4 | 17 | 3 | 3 |
| 23 | 50.2 | 5 | 8 | 3 | 10 | 2 | 2 |
| 24 | 73.4 | 6 | 7 | 5 | 5 | 2 | 2 |
| 25 | 62 | 5 | 6 | 2 | 22 | 3 | 3 |
| 26 | 36.2 | 4 | 3 | 2 | 20 | 2 | 1 |
| 27 | 44.1 | 6 | 6 | 3 | 9 | 1 | 2 |
| 28 | 55 | 1 | 2 | 2 | 25 | 2 | 1 |
| 29 | 41.8 | 5 | 1 | 3 | 17 | 2 | 2 |
| 30 | 33.4 | 6 | 8 | 2 | 21 | 1 | 1 |
Sekarang mari kita interpretasi arti hasil analisis itu step-by-step.
Langkah-langkah Analisis dengan SPSS
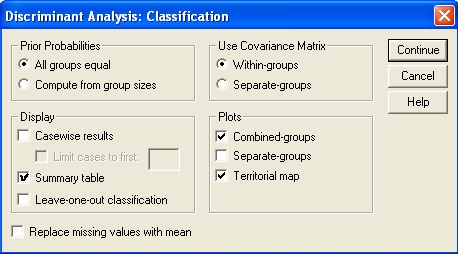
Prosedur yang digunakan sama saja dengan analisis diskriminan dua grup. Hanya saja, pada langkah kedua, pada kotak dialog Define range, pada sel minimum isikan angka 1 dan pada sel minimum isikan angka 3. Lalu, ikuti langkah ke-3 dan langkah ke-4. Setelah langkah ke-4, tambahkan satu langkah (sebelum langkah ke-5 pada), yaitu meng-klik menu Classify agar muncul kotak dialog Classification. Lalu, tandai pilihan seperti pada gambar berikut. Kemudian, klik Continue.
Interpretasi Output
Group Statistics
Group statistik berisikan data tentang rata-rata dan standar deviasi setiap grup dan total sampel. Data ini memberikan gambaran awal tentang diskriminasi sampel. Artinya, sampel yang kita miliki akan terdiskriminasi dengan baik kalau data memenuhi dua hal. Pertama, rata-rata variabel setiap grup berbeda . Kedua, kalau standar deviasi dalam grup lebih rendah dibanding standar deviasi total karena kita mengharapkan homogenitas dalam grup yang tinggi (standar deviasi lebih rendah), sebaliknya antara grup yang satu dengan grup lainnya, kita mengharapkan heterogenitas yang tinggi (standar deviasi lebih tinggi).
| Tabel 2. Group Statistics | |||||
| Tujuan tempat berlibur | Mean | Std. Deviation | Valid N (listwise) | ||
| Unweighted | Weighted | ||||
| 1.00 | Pendapatan keluarga | 40.2455 | 7.17027 | 11 | 11.000 |
| Pentingnya liburan bagi anak | 4.0909 | 2.02260 | 11 | 11.000 | |
| Sikap terhadap jalan-jalan | 4.4545 | 1.96792 | 11 | 11.000 | |
| Jumlah anak | 2.8182 | .87386 | 11 | 11.000 | |
| Rata-rata usia anak | 15.3636 | 5.29665 | 11 | 11.000 | |
| Lama berumah tangga | 1.6364 | .67420 | 11 | 11.000 | |
| 2.00 | Pendapatan keluarga | 51.9500 | 9.48042 | 10 | 10.000 |
| Pentingnya liburan bagi anak | 4.5000 | 2.17307 | 10 | 10.000 | |
| Sikap terhadap jalan-jalan | 4.7000 | 2.49666 | 10 | 10.000 | |
| Jumlah anak | 3.3000 | 1.05935 | 10 | 10.000 | |
| Rata-rata usia anak | 11.9000 | 5.30094 | 10 | 10.000 | |
| Lama berumah tangga | 1.8000 | .63246 | 10 | 10.000 | |
| 3.00 | Pendapatan keluarga | 64.1444 | 8.64525 | 9 | 9.000 |
| Pentingnya liburan bagi anak | 6.1111 | 1.26930 | 9 | 9.000 | |
| Sikap terhadap jalan-jalan | 5.7778 | 1.71594 | 9 | 9.000 | |
| Jumlah anak | 3.4444 | .72648 | 9 | 9.000 | |
| Rata-rata usia anak | 17.0000 | 3.08221 | 9 | 9.000 | |
| Lama berumah tangga | 2.6667 | .50000 | 9 | 9.000 | |
| Total | Pendapatan keluarga | 51.3167 | 12.80385 | 30 | 30.000 |
| Pentingnya liburan bagi anak | 4.8333 | 2.01859 | 30 | 30.000 | |
| Sikap terhadap jalan-jalan | 4.9333 | 2.09981 | 30 | 30.000 | |
| Jumlah anak | 3.1667 | .91287 | 30 | 30.000 | |
| Rata-rata usia anak | 14.7000 | 5.05248 | 30 | 30.000 | |
| Lama berumah tangga | 2.0000 | .74278 | 30 | 30.000 | |
Rata-rata setiap variabel berbeda pada ketiga grup merupakan indikasi bahwa sampel memang layak didiskriminasi. Namun, data standar deviasi tidak memenuhi syarat ideal di atas. Sebab, standar deviasi X2 dan X5 lebih tinggi pada grup 1 dibanding pada total sampel. Pada group statistics terlihat bahwa standar deviasi X2, X3, X4, dan X5 pada grup 2 lebih tinggi ketimbang pada total sampel. Hasil ini menimbulkan kecurigaan jangan-jangan keempat variabel tidak memiliki peran diskriminasi. Untuk memastikannya, simak penjelasan test of equality of group means berikut.
Test of Equality of Group Means
Kebimbangan di atas terjawab dengan memeriksa signifikansi setiap variabel secara sendiri-sendiri. Dengan memakai uji F, terlihat hanya X1 dan X6 yang memiliki signifikansi melewati batas µ=0.05 – batas tingkat kesalahan maksimal yang paling banyak dipakai.
| Tabel 3. Tests of Equality of Group Means | |||||
| Wilks’ Lambda | F | df1 | df2 | Sig. | |
| Pendapatan keluarga | .404 | 19.912 | 2 | 27 | .000 |
| Pentingnya liburan bagi anak | .815 | 3.066 | 2 | 27 | .063 |
| Sikap terhadap jalan-jalan | .926 | 1.082 | 2 | 27 | .353 |
| Jumlah anak | .909 | 1.358 | 2 | 27 | .274 |
| Rata-rata usia anak | .823 | 2.899 | 2 | 27 | .072 |
| Lama berumah tangga | .634 | 7.790 | 2 | 27 | .002 |
Hipothesis nol yang diuji menyatakan bahwa koefisien diskriminasi setiap variabel sama dengan nol. Pada tingkat kesalahan 0,05 (kepercayaan 95%), kita tidak punya bukti untuk menolak hipothesis itu pada variabel-variabel X2, X3, X4 dan X5.
Mau diapakan variabel-variabel itu? Tergantung tujuan kita. Kalau tujuannya adalah menguji hipothesis tentang pengaruh variabel-variabel independen terhadap independen, maka semua variabel harus dilibatkan. Akan tetapi, kalau untuk membangun model diskriminasi yang efektif, variabel-variabel tersebut dapat dieliminasi. Akan tetapi, ada baiknya kita melakukan metoda stepwise discriminant analysis untuk memastikan apakah model baru yang dibangun (dengan membuang variabel-variabel itu satu demi satu atau sekaligus) lebih baik dari model awal kita.
Pooled Within-Group Matrices
Data ini menunjukkan korelasi antar-variabel. Idealnya, secara teori, dalam analisis diskriminan, tidak terdapat kolinearitas antar-variabel. Namun, pada Tabel 4 terlihat bahwa korelasi antara X1 dan X4 (r=0,353), X2 dan X5 (r=-0,387), X5 dan X4 (r=-0,294) serta antara X3 dan X4 (r=0,288). Angka-angka ini mencurigakan cukup tinggi, yang menandakan adanya multikoniaritas di antara variabel-variabel tersebut, yang membuat model tidak efisien. Apakah kecurigaan ini terbukti bila dilakukan stepwise discriminant analysis, dengan mana variabel-variabel independen yang terlibat hubungan sesama (multikolinearitas) dapat dikeluarkan.
Tabel 4. Pooled Within-Groups Matrices
| Pendapatan keluarga | Pentingnya liburan bagi anak | Sikap terhadap jalan-jalan | Jumlah anak | Rata-rata usia anak | Lama berumah tangga | ||
| Correlation | Pendapatan keluarga | 1.000 | .022 | .273 | .353 | -.216 | -.231 |
| Pentingnya liburan bagi anak | .022 | 1.000 | .077 | -.017 | -.387 | .118 | |
| Sikap terhadap jalan-jalan | .273 | .077 | 1.000 | .288 | -.082 | -.244 | |
| Jumlah anak | .353 | -.017 | .288 | 1.000 | -.294 | .014 | |
| Rata-rata usia anak | -.216 | -.387 | -.082 | -.294 | 1.000 | .397 | |
| Lama berumah tangga | -.231 | .118 | -.244 | .014 | .397 | 1.000 | |
Box’s M
Box’s M test equality of group means bertujuan untuk mengetahui apakah ketiga kelompok sampel berasal dari populasi yang sama. Memang, syaratnya adalah semua unit analisis (anggota sampel) haruslah berasal dari populasi yang sama. Input yang digunakan adalah covariance. Box’s M menguji Ho: Covariance ketiga grup adalah sama. Untuk memutuskan menerima ataukah menolah Ho digunakan nilai Box’s M yang didekati dengan nilai F. Dalam analisis diskriminan yang kita lakukan, nilai Box’s M=57.282 yang didekati dengan nilai F=0.904, dengan nilai Sig.=0.649. Dengan demikian, pada ∝=0.05, cukup bukti untuk menerima H0 bahwa covariance ketiga grup adalah sama.
Tabel 5. Nilai Box’s M
| Box’s M | 57.282 | |
| F | Approx. | .904 |
| df1 | 42 | |
| df2 | 2038.359 | |
| Sig. | .649 | |
Eigenvalues
Dari nilai eigenvalue yang tertera pada Tabel 6 terlihat bahwa fungsi 1 (function 1), dengan eigenvalue sebesar 2,757, dapat menjelaskan 91 % varian. Hal ini menunjukkan bahwa fungsi 1 memiliki kekuatan diskriminasi yang mumpuni. Sebaliknya, fungsi 2 (function 2), dengan eigenvalue sebesar 0,274, hanya dapat menjelaskan 9% varian. Memang, dalam analisis diskriminan berganda, tidak semua fungsi signifikan (Malhotra, 2020). Biasanya, kekuatan fungsi dalam analisis diskriminan ganda memang tidak sama.
Tabel 6. Eigenvalues
| Function | Eigenvalue | % of Variance | Cumulative % | Canonical Correlation |
| 1 | 2.757a | 91.0 | 91.0 | .857 |
| 2 | .274a | 9.0 | 100.0 | .463 |
| a. First 2 canonical discriminant functions were used in the analysis. | ||||
Canonical correlation menunjukkan keeratan hubungan antara variabel-variabel independen dengan persamaan 1 (sebesar 0.857) dan persamaan 2 (sebesar 0.463).Canonical Correlation
Wilks’ Lamda
Apakah kedua fungsi signifikan? Lihat nilai Wilks Lambda pada Tabel 7. Terlihat nilai Wilks’ Lambda untuk kedua fungsi (1 through 2) sebesar 0,209. Nilai ini ditransfer menjadi nilai Chi-square sebesar 38,355 yang memiliki tingkat signifikansi 0,000. Tingkat signifikansi ini tentunya jauh di atas 0,05 yang umumnya diterima sebagai batas maksimal tingkat kesalahan.
Tabel 7. Wilks’ Lambda
| Test of Function(s) | Wilks’ Lambda | Chi-square | df | Sig. |
| 1 through 2 | .209 | 38.355 | 12 | .000 |
| 2 | .785 | 5.925 | 5 | .314 |
Sekiranya fungsi 1 dikeluarkan, maka fungsi 2 hanya memiliki Wilks’ Lambda sebesar 0.785, yang kalau dalam chi-square nilainya menjadi 5,517 dengan tingkat signifikansi 0,314 dan tergolong tidak signifikan. Jadi, kalau hanya mengandalkan fungsi 2, maka proses diskriminasi tidak berguna.
Standardized Canonical Discriminant Function Coefficient
Pada Tabel 8 terlihat bahwa fungsi 1 memiliki koefisien yang relatif besar pada variabel X1 dan X6. Artinya, kedua variabel inilah yang paling berperan dalam melakukan diskriminasi melalui fungsi 1. Fungsi 2 memiliki koefisien yang besar pada variabel X2 dan X5.
Tabel 8. Standardized Coefficients
| Function | ||
| 1 | 2 | |
| Pendapatan keluarga | .907 | -.316 |
| Pentingnya liburan bagi anak | .234 | .609 |
| Sikap terhadap jalan-jalan | .102 | .114 |
| Jumlah anak | -.146 | .143 |
| Rata-rata usia anak | .134 | 1.128 |
| Lama berumah tangga | .604 | -.281 |
Structure Matrix
Data pada structure matrix (Tabel 9) menunjukkan korelasi antara setiap variabel dengan kedua fungsi diskriminan. Sekalipun komputer sudah memberikan hasilnya, data ini dapat kita hitung secara manual. Caranya, dengan meng-korelasikan nilai-nilai setiap variabel secara sendiri-sendiri dengan skor masing-masing fungsi diskriminan.
Tabel 9. Structure Matrix
| Function | ||
| 1 | 2 | |
| Pendapatan keluarga | .720* | -.400 |
| Lama berumah tangga | .448* | .287 |
| Pentingnya liburan bagi anak | .284* | .139 |
| Sikap terhadap jalan-jalan | .168* | .092 |
| Rata-rata usia anak | .122 | .797* |
| Jumlah anak | .169 | -.281* |
Dari structure matrix terlihat lebih condong ke fungsi mana setiap variabel. Lihat tanda bintang pada koefisien korelasi. Tanda bintang itu menandai dengan fungsi mana setiap variabel berkoalisi. Fungsi 1 berkorelasi paling tinggi dengan (sesuai urutan) X1, X6, X2 dan X3. Dua variabel lain, yaitu X5 dan X4 (sesuai urutan) berkorelasi paling dekat dengan fungsi 2.
Canonical Discriminant Function Coefficients
Data ini menyatakan koefisien setiap variabel dalam kedua fungsi. Sekali pun hanya X1, X6, X2 dan X3 yang berkoalisi dengan fungsi 1, tetapi dalam model diskriminan fungsi 1 semua variabel dilibatkan. Demikian pula pada model diskriminan fungsi 2.
Data pada output SPSS sebenarnya tidak salah. Namun, karena hanya tiga angka di belakang koma, kalau data ini dipakai untuk membangun model untuk menghitung Z score, maka skor diskriminan yang dihasilkan perhitungan manual bisa berbeda dari hasil SPSS, sekali pun tidak berbeda jauh. Supaya puas, kopi dulu canonical discriminant function dari output SPSS ke Excel. Pada Excel, kita bisa mengatur berapa pun angka di belakang koma. Pada Tabel 10 kita peroleh koefisien lima angka di belakang koma dari Excel.
Tabel 10. Canonical Discriminant Function Coefficients Lima Angka di Belakang Koma.
| Function | ||
| 1 | 2 | |
| X1 | 0.107589 | -0.03744 |
| X2 | 0.123814 | 0.32258 |
| X3 | 0.048805 | 0.05467 |
| X4 | -0.161365 | 0.15813 |
| X5 | 0.028217 | 0.23740 |
| X6 | 0.985852 | -0.45767 |
| (Constant) | -8.235827 | -2.98282 |
Unstandardized coefficients
Dengan data pada tabel, kedua fungsi memiliki persamaan sebagai berikut.

Dengan kedua persamaan ini, pada setiap responden, kita dapat menghitung skor diskriminan dengan fungsi 1 maupun untuk fungsi 2. Mari kita contohkan pada Responden 1. Ini datanya dari Tabel 1: X1=47.1, X2=2, X3=5, X4=3, X5=14, dan X6=1.
D1=-8.235827–0.107589(47.1)+0.123814(2)+ 0.048805(5)-0.161365(3)+0.028217(14)+0.985852(1)=-1.77994
D2=-2.98282–0.03744(47.1)+0.32258(2)+ 0.05467(5)+0.15813(3)+0.23740(14)-0.45767(1)=-0.48741
Dengan cara demikianlah skor diskriminan semua responden diperoleh, seperti ditampilkan pada Tabel 12 untuk Grup 1. Buat apa skor ini? Skor ini dipakai untuk menempatkan responden 1 dalam diagram kartesius dengan koordinat (-1.77994,-0.48741). Lihat pada pembahasan tentang teritoral map.
Prediksi Keanggotaan Setiap Responden
Bagaimana kita memprediksi keanggotaan setiap responden? Untungnya, data tentang keanggotaan responden juga diberikan oleh komputer berdasarkan peluang. Responden 1 aslinya grup 1, diprediksi masuk grup 1 (kelompok yang berlibur di dalam kota) karena memang peluang ke grup 1 paling besar, yaitu 0,672. Responden 2, diprediksi masuk grup 3. Aslinya memang grup 3 (kelompok yang berlibur ke luar pulau). Peluang responden 2 masuk grup 3 sangat besar, yakni 0,936. Sedangkan ke grup 1 dan grup 2, peluang keanggotaan responden 2 kecil, masing-masing hanya 0,001 dan 0,063.
Responden 9 merupakan salah satu yang salah prediksi. Aslinya, dia ini masuk grup 3, akan tetapi tetapi diprediksi masuk grup 2 (kelompok yang berlibur ke luar kota). Salah prediksi seperti ini biasa dalam analisis diskriminan.
Functions at Group Centroid
Data ini menjelaskan rata-rata skor setiap grup, baik berdasarkan fungsi satu maupun berdasarkan fungsi dua. Mari kita ambil skor diskriminan dari Tabel 6.6 untuk menghitung centroid. Karena keperluannya hanya untuk memperagakan, maka perhitungan hanya dilakukan untuk grup 1. Coba lakukan pada grup 2 dan 3 sebagai latihan.
Tabel 11. Functions at Group Centroids
| Tujuan tempat berlibur | Function | |
| 1 | 2 | |
| 1.00 | -1.590 | .418 |
| 2.00 | -.282 | -.696 |
| 3.00 | 2.257 | .263 |
Tabel 12. Perhitungan Centroid Grup 1.
| Responden | Skor diskriminan Fungsi 1 | Skor diskriminan Fungsi 2 |
| 1 | -1.78 | -0.487 |
| 3 | -2.193 | -0.965 |
| 8 | -1.912 | -0.311 |
| 10 | -2.029 | 1.004 |
| 11 | -2.92 | -0.682 |
| 13 | -0.74 | 1.156 |
| 16 | -1.035 | 0.571 |
| 19 | -1.397 | -0.668 |
| 26 | -1.486 | 1.265 |
| 28 | 0.257 | 0.726 |
| 30 | -2.253 | 2.984 |
| Rata-rata | -1.590 | 0.418 |
Classification Statistics
Cendroid grup diperlihatkan dalam territorial map. Dengan menggunakan fungsi 1 dan fungsi 2 sebagai sumbu, setiap grup memiliki memiliki posisi, di mana titik koordinatnya adalah cendroid itu sendiri.
Berbeda dengan analisis diskriminan dua grup, pada model tiga grup atau lebih, cutting score tidak lagi dapat dipakai sebagai kriteria untuk memprediksi keanggotaan setiap objek (responden).
Untungnya, program sudah melakukan prediksi, selain memberikan peluang keanggotaan setiap objek.
Satu alat lagi untuk melihat keanggotaan setiap objek adalah dengan memeriksa peta teritorial. Pada peta ini diperlihatkan teritorial setiap grup. Kalau ada anggota grup masuk pada teritorial grupnya, berarti keanggotaan anggota itu diprediksi dengan tepat. Kalau aslinya anggota grup 1, tetapi masuk teritori grup 2, berarti keanggotaan anggota itu salah prediksi.
Bagaimana melihat apakah anggota-anggota setiap grup berada di dalam ataukah di luar teritorialnya? Caranya dengan menggabungkan teritorial map dengan scattergram. Sebelumnya, skala kedua gambar itu harus disamakan terlebih dahulu agar sesuai.
Pertama-tama, kita buat dulu Scattergram semua responden berdasarkan skor D1 dan D2 yang dijadikan sebagai titik koordinat. Skor D1 dan D2 ada di tabel SPSS ya? Cara membuat scattergram dengan SPSS dapat dilihat di video ini (underconstruction). Ini Scattergram-nya.

Ini Teritorial Map yang diberikan SPSS

Kalau teritorial map ditimpakan ke scattergram, hasilnya begini.

Terlihat pada gambar di atas, ada 11 anggota Grup 1 yang diprediksi tepat masuk Grup 1. Yang salah prediksi masuk Grup 2 ada satu, yaitu responden nomor 28. Anggota Grup 2 yang diprediksi tepat ke Grup 2 adalah enam responden, dua salah prediksi ke Grup 1 (nomor 27 dan 29) dan ke Grup 3 dua responden (nomor 21 dan 24). Anggota Grup 3 yang tepat diprediksi ke Grup 3 ada delapan orang. Satu responden salah prediksi ke Grup 2, yaitu nomor 9. Hasil ini diperlihatkan pada Tabel 13 di bawah.
Dari 10 anggota grup 2, yang masuk ke teritorial grup 1 ada 2 dan ke teritorial grup 3 juga 2 anggota. Yang diprediksi dengan tepat adalah 6 anggota (60%). Dari 9 anggota grup 3, masuk wilayah grup 2 ada satu. Jadi, yang diprediksi tepat 8 anggota (88,89%).
Akhirnya, dari 30 total sampel, 24 orang diprediksi secata tepat keanggotaannya. Artinya, hit ratio adalah 80%. Kesimpulan yang sama terdapat pada classification result (Output 11). Pertanyaannya, apakah kedua fungsi akurat dalam melakukan tugasnya?
Tabel 13. Classification Resultsa
| Tujuan tempat berlibur | Predicted Group Membership | Total | ||||
| 1.00 | 2.00 | 3.00 | ||||
| Original | Count | 1.00 | 10 | 1 | 0 | 11 |
| 2.00 | 2 | 6 | 2 | 10 | ||
| 3.00 | 0 | 1 | 8 | 9 | ||
| % | 1.00 | 90.9 | 9.1 | .0 | 100.0 | |
| 2.00 | 20.0 | 60.0 | 20.0 | 100.0 | ||
| 3.00 | .0 | 11.1 | 88.9 | 100.0 | ||
a. 80.0% of original grouped cases correctly classified.
REFERENSI
Malhotra, N.K. (2020). Marketing Research: An Applied Orientation. Harlow, United Kingdom: Pearson Education