Last updated on May 9, 2023 by Bilson Simamora
Kalau jumlah objek banyak, misalnya sepuluh merek, akan ada 10(10-1)/2=45 pasangan merek. Tentu, membuat peringkat kesamaan sedemikian banyak pasangan merupakan pekerjaan merepotkan. Oleh karena itu, teknik dengan menggunakan skala numerik ataupun semantic differential, dapat dipertimbangkan.
Berikan pendapat anda tentang kemiripan pasangan-pasangan koran nasional berikut:
| Kompas-Koran Tempo | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Republika | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Suara Pembaruan | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Bisnis Indonesia | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Pos Kota | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Kompas-Rakyat Merdeka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Republika | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Suara Pembaruan | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Bisnis Indonesia | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Pos Kota | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Koran Tempo-Rakyat Merdeka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Republika-Suara Pembaruan | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Republika-Bisnis Indonesia | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Republika-Pos Kota | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Republika-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Republika-Rakyat Merdeka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Suara Pembaruan-Bisnis Indo. | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Suara Pembaruan-Pos Kota | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Suara Pembaruan-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Suara Pembaruan-Rakyar Mrd | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Bisnis Indonesia- Pos Kota | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Bisnis Indonesia-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Bisnis Indonesia-Rakyat Mrdka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Pos Kota-Lampu Merah | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Pos Kota-Rakyat Merdeka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
| Lampu Merah-Rakyat Merdeka | Sangat beda 1 2 3 4 5 6 7 Sangat mirip |
Metoda ini menguntungkan karena lebih mudah, sebab responden tidak perlu membandingkan peringkat satu pasangan dengan pasangan lain. Masalahnya, dengan metoda ini, kita tidak mengetahui peringkat kemiripan pasangan, sebab terdapat kemungkinan adanya skor yang sama.
Tabel 8.2 berisikan data mentah yang diperoleh dari konsumen. Untuk pengolahan, data ini kita ubah menjadi data ranking, seperti pada Tabel 8.2A. Cara meranking tidak dijelaskan di sini. Konsep tersebut dapat didalami pada buku-buku statistika.
| Bisnis Indonesia | Kompas | Koran Tempo | Lampu Merah | Suara Pembaruan | Pos Kota | Rakyat Merdeka | Republika | |
| Bisnis Ind | . | . | . | . | . | . | . | |
| Kompas | 6 | . | . | . | . | . | . | |
| Koran Tempo | 6 | 6 | . | . | . | . | . | |
| Lampu Merah | 1 | 1 | 1 | . | . | . | . | |
| Pembaruan | 4 | 6 | 7 | 1 | . | . | . | |
| Pos Kota | 1 | 1 | 1 | 6 | 1 | . | . | |
| Rakyat Merdeka | 1 | 1 | 1 | 5 | 3 | 5 | . | |
| Republika | 4 | 4 | 5 | 1 | 2 | 3 | 1 |
Langkah-langkah Analisis
1. Ketik data di atas di SPSS. Urutan nama merek pada kolom harus menurut abjad untuk menghindari interpretasi ‘missing data‘ oleh SPSS. Tampilan data adalah seperti di bawah ini. Perlu diketahui bahwa data ini hanya dari seorang responden.

2. Pada menu utama SPSS, pilih analyze, lalu Scale, setelah itu klik multimension scaling (PROXSCALL). Dalam SPSS, ada dua pilihan MDS. Selain PROXSCALL, satu lagi adalah ASCALL. Untuk bentuk matrik seperti di atas, PROXSCALL memberikan hasil lebih baik karena ada koordinat merek-merek mudah di-copy. Jadi, kita pilih program ini.
3. Pada kotak dialog yang muncul, pilih: The data are proximities, One matrix sources, Proximities are in a matrix across column, lalu klik Define.
4. Pada kotak dialog yang muncul, masukkan semua merek pada sel proximities.
5. Klik Model. Pada langkah ini:
- Pastikan Shape adalah Lower-triangular matrix. Parena pola data kita dapat membentuk dua segitiga, yaitu di atas dan di bawah diagonal. Data di atas mengambil pola setiga bagian bawah.
- Pastikan Proximities adalah Similarities. SPSS menginterpretasi bahwa semakin tinggi angka, semakin tinggi nilainya. Nah, dengan skala yang kita gunakan, semakin tinggi nilai data, semakin tinggi similarity (kesamaan).
- Pastikan Proximities transformation adalah Ratio.
6. Klik Plot dan tandai Common space.
7. Klik Output dan tandai Comonspace coordinates, Multiple stress measure, dan Distances.
8. Klik OK. Sekarang kita interpretasi hasilnya.
Goodness of Fit
Apakah model MDS kita baik? Karena hanya menggunakan seorang responden, kita dapat menggunakan Normalized Raw Stress dan Dispersion Accounted For (D.A.F.) dari tabel berikut.
| Stress and Fit Measures | |
| Normalized Raw Stress | .07524 |
| Stress-I | .27430a |
| Stress-II | .81850a |
| S-Stress | .18375b |
| Dispersion Accounted For (D.A.F.) | .92476 |
| Tucker’s Coefficient of Congruence | .96165 |
| PROXSCAL minimizes Normalized Raw Stress. | |
| a. Optimal scaling factor = 1.081. | |
| b. Optimal scaling factor = .949. | |
Stress mengindikasikan proporsi varian perbedaan (disparity) yang tidak dijelaskan oleh model. Semakin rendah stress, semakin baik model MDS yang dihasilkan”. Pertanyaannya, sampai nilai berapa stress masih mengindikasikan model yang baik? Untuk menjawab pertanyaan ini, Dugard et al. (2010) memberi ketentuan seperti di bawah ini.
| 100 X Stress (Percent) | Goodness of Fit |
| 20% or above | Poor |
| 10%-19.9% | Fair |
| 5%-9.9% | Good |
| 2.5%-4.9% | Excellent |
| 0%-2.4% | Near Perfect |
Pada output di atas, ada tiga nilai stress, yaitu Normalized Raw Stress, Stress I, Stress II, dan S-Stress. Yang menjadi perhatian kita adalah S-Stress dan Normalized Raw Stress. S-stress dihitung berdasarkan squared distance, sedangkan Normalized Raw Stress (NRStress) dihitung berdasarkan distances. Yang terbaik di antara keduanya adalah NRStress (Borg & Groenen, 1997). Pada kasus kita, nilai NR-Stress=.07524 adalah good.
Dispersion Accounted For (DAF) digunakan untuk mengevaluasi kesesuaian peta persepsi dengan data sumbernya. DAF diperoleh dari NR-Stress dengan rumus: DAF = 1 – NRStress. Dengan demikian, DAF dapat berkisar dari 0 hingga 1 dan nilai yang lebih tinggi menunjukkan kecocokan yang lebih baik. Pada model kita, DAF=.92476. Lagi pula, kalau menurut NRStress, model MDS adalah good-fit, maka DAF harus menunjukkan hasil yang sama.
Nilai Tucker’s Coefficient of Congruence=0.96165. Nilai menyatakan korelasi antar dimensi MDS multi sampel. Karena data kita adalah one sample, maka nilai ini tidak perlu diinterpretasi.
Perceptual Map
Program SPSS menghasilkan perceptual map dan koordinatnya seperti di bawah ini. Coba kita perhatikan Kompas. Terlihat bahwa koran Lampu Merah menempati posisi sendiri.
| Dimension | ||
| 1 | 2 | |
| Bisnis_Indonesia | -.112 | .174 |
| Kompas | -.358 | .603 |
| Koran_Tempo | -.212 | -.705 |
| Lampu_Merah | -.818 | .006 |
| Suara_Pembaruan | .877 | .065 |
| Pos_Kota | .427 | -.367 |
| Rakyat_Merdeka | -.145 | -.233 |
| Republika | .342 | .457 |
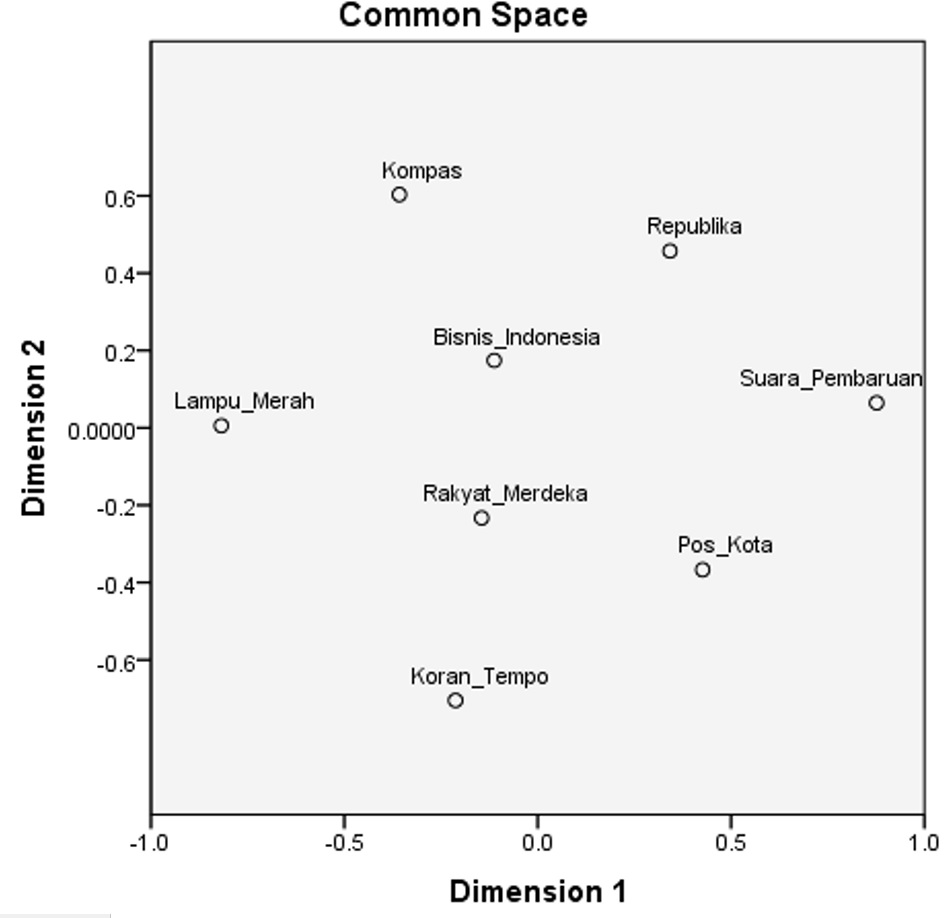
Semakin sama merek, semakin tinggi persaingan di antara mereka. Bila premis ini dipakai, maka yang bersaing paling dekat adalah yang memilik jarak (distance) paling rendah, yaitu antara Bisnis Indonesia dan Rakyat Merdeka. Harap diingat bahwa data yang dioleh adalah hasil simulasi untuk pembelajaran dan tidak mencerminkan keadaan sebenarnya.
| Distances | ||||||||
| Bisnis Indonesia | Kompas | Koran Tempo | Lampu Merah | Suara Pembaruan | Pos Kota | Rakyat Merdeka | Republika | |
| Bisnis_Indonesia | .000 | |||||||
| Kompas | .494 | .000 | ||||||
| Koran_Tempo | .885 | 1.316 | .000 | |||||
| Lampu_Merah | .726 | .754 | .934 | .000 | ||||
| Suara_Pembaruan | .995 | 1.347 | 1.333 | 1.696 | .000 | |||
| Pos_Kota | .764 | 1.247 | .723 | 1.299 | .623 | .000 | ||
| Rakyat_Merdeka | .409 | .863 | .476 | .714 | 1.064 | .587 | .000 | |
| Republika | .535 | .715 | 1.288 | 1.245 | .663 | .828 | .845 | .000 |
Bagaimana kalau responden lebih dari satu? Kita bisa menggunakan prosedur seperti yang dijelaskan pada link ini.
- MDS Non-Atribut berbasis Ranking Similarity
- MDS dengan Anchor Point Clustering Method
- MDS Similarity berbasis Atribut
- MDS with Comparative-based Preference
- MDS with Attitude-based Preference
REFERENSI
Borg, I., Groenen, P. (1997). MDS fit measures, their relations, and some algorithms. In: Modern Multidimensional Scaling. Springer Series in Statistics. Springer, New York, NY. https://doi.org/10.1007/978-1-4757-2711-1_11
Dugard, P., Todman, J., & Staines, H. (2010). Approaching Multivariate Analysis. A Practical Introduction. Second Edition. Routledge: New York. This text has example analyses using SPSS.