Last updated on May 9, 2023 by Bilson Simamora
Membuat Ranking | Multiple Matrix Source | One Matrix Source | Stress and Fit Measures | Memberi Nama Dimensi
Pada postingan ini telah digambarkan adanya dua pendekatan MDS, yaitu pendekatan atribut dan non-atribut. Dengan pendekatan atribut, maka pembuatan peta persepsi dilakukan dengan membandingkan atribut-atribut sebuah merek dibanding merek lain. Dalam pendekatan non-atribut, yang kita gunakan ada dua, yaitu persepsi kesamaan (similarity approach) antar merek dan preferensi (preference approach) terhadap merek-merek yang berada dalam suatu competitive framework.
Ada beberapa cara mengukur kesamaan, yaitu meranking, menggunakan skala numerik atau semantic differential, mengelompokkan secara subjektif, anchoring clustering method, membandingkan pasangan dan mengukur perilaku secara langsung (direct behavior method). Dua metoda pertama paling banyak dibahas dalam buku-buku riset pemasaran.
Berikut ini dilakukan pembahasan pada empat metoda pertama. Dua metoda terakhir tidak dibahas karena tidak praktis dalam penerapannya.
Membuat Ranking
Kita bisa meminta responden untuk meranking semua pa-sangan objek-objek yang mungkin (all possible pairs). Misalkan kita meriset delapan merek: Sosro, Tekita, Es Tea, Fruit Tea, Lipton Ice Tea, dan Fresh Tea. Jika dipasang-pasangkan akan ada 15 pasangan, yang ditampilkan dalam pertanyaan (yang disertai simulasi jawaban) sebagai berikut:
Instruksi: Berikan peringkat (ranking) tingkat kesamaan pasangan-pasangan merek teh botol berikut. Catatan: peringkat 1 adalah yang paling mirip.
Tabel Hasil pengisian kuesioner seorang responden
| Pasangan Merek | Ranking |
| Sosro vs. Tekita | 5 |
| Sosro vs. Es Tea | 6 |
| Sosro vs. Fruit Tea | 14 |
| Sosro vs. Lipton Ice Tea | 15 |
| Sosro vs. Fresh Tea | 7 |
| Tekita vs. Es Tea | 1 |
| Tekita vs. Fruit Tea | 8 |
| Tekita vs. Lipton Ice Tea | 9 |
| Tekita vs. Fresh Tea | 2 |
| Es Tea vs. Fruit Tea | 10 |
| Es Tea vs. Lipton Ice Tea | 11 |
| Es Tea vs. Fresh Tea | 4 |
| Fruit Tea vs. Lipton Ice Tea | 3 |
| Fruit Tea vs. Fresh Tea | 12 |
| Lipton Ice Tea vs. Fresh Tea | 13 |
Dengan pertanyaan serta simulasi data di atas, kita hasilkan data seperti pada Tabel 8.1. Lalu, dengan data ini, kita hasilkan perceptual map Gambar 8.3.
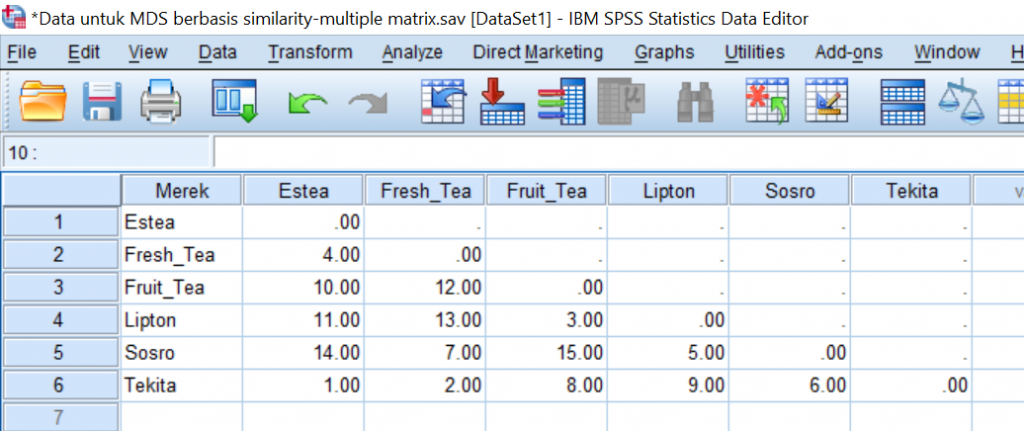
Tabel 2. Simulasi Peringkat Kesamaan Merek-merek Teh Botol dari seorang responden
| Estea | Fresh Tea | Fruit Tea | Lipton | Sosro | Tekita | |
| Estea | ||||||
| Fresh Tea | 4 | . | . | . | . | |
| Fruit Tea | 10 | 12 | . | . | . | |
| Lipton | 11 | 13 | 3 | . | . | |
| Sosro | 14 | 7 | 15 | 5 | . | |
| Tekita | 1 | 2 | 8 | 9 | 6 |
Download data dari sini. Data ini dari beberapa responden. Perlu diingat bahwa kita bisa mengolah MDS dengan jenis data seperti ini dari seorang (one matrix source) atau lebih dari satu responden (multiple matrix source). Kali ini kita mengolah data berupa multile matrix source.
Multiple Matrix Source
Langkah-langkah
1. Download data SPSS dari sini dan buka di SPSS. Tampil datanya seperti ini.

2. Pada menu utama SPSS, pilih analyze, lalu Scale, setelah itu klik multimension scaling (PROXSCALL). Dalam SPSS, ada dua pilihan MDS. Selain PROXSCALL, satu lagi adalah ASCALL. Untuk bentuk matrik seperti di atas, PROXSCALL memberikan hasil lebih baik karena ada koordinat merek-merek mudah di-copy. Jadi, kita pilih program ini.
3. Pada kotak dialog yang ditampilkan, pilih: The data are proximities, Multiple matrix sources, Proximities are stacked in a matrix across column, lalu klik Define.
4. Pada kotak dialog yang muncul, masukkan semua merek pada sel proximities.
5. Klik Model. Pada langkah ini:
- Pastikan Shape adalah Lower-triangular matrix. Parena pola data kita dapat membentuk dua segitiga, yaitu di atas dan di bawah diagonal. Data di atas mengambil pola setiga bagian bawah.
- Pastikan Proximities adalah Dissimilarities. Bukankah judul menyatakan bahwa perceptual map yang kita bangun adalah berbasis Similarity? Betul. Namun, SPSS menginterpretasi bahwa semakin tinggi angka, semakin tinggi nilainya. Nah, pada data kita, semakin rendah angka, semakin tinggi similarity (kesamaan). Semakin tinggi angka, semakin tinggi dissimilarity (perbedaan).
- Pastikan Proximities transformation adalah Ratio.
6. Klik Plot dan tandai Common space.
7. Klik Output dan tandai Comonspace coordinates, Multiple stress measure, dan Distances.
8. Klik OK. Sekarang kita interpretasi hasilnya.
Interpretasi Output
Stress and Fit Measures
| Normalized Raw Stress | .03689 |
| Stress-I | .19206a |
| Stress-II | .54700a |
| S-Stress | .09282b |
| Dispersion Accounted For (D.A.F.) | .96311 |
| Tucker’s Coefficient of Congruence | .98138 |
| PROXSCAL minimizes Normalized Raw Stress. | |
| a. Optimal scaling factor = 1.038. | |
| b. Optimal scaling factor = 1.059. | |
Stress
Stress mengindikasikan proporsi varian perbedaan (disparity) yang tidak dijelaskan oleh model. Semakin rendah stress, semakin baik model MDS yang dihasilkan”. Pertanyaannya, sampai nilai berapa stress masih mengindikasikan model yang baik? Untuk menjawab pertanyaan ini, Dugard et al. (2010) memberi ketentuan seperti di bawah ini.
| 100 x Stress (Percent) | Goodness of Fit |
| 20% or above | Poor |
| 10%-19.9% | Fair |
| 5%-9.9% | Good |
| 2.5%-4.9% | Excellent |
| 0%-2.4% | Near Perfect |
Pada output di atas, ada tiga nilai stress, yaitu Normalized Raw Stress, Stress I, Stress II, dan S-Stress. Yang menjadi perhatian kita adalah S-Stress dan Normalized Raw Stress. S-stress dihitung berdasarkan squared distance, sedangkan Normalized Raw Stress (NRStress) dihitung berdasarkan distances. Yang terbaik di antara keduanya adalah NRStress (Borg & Groenen, 1997). Pada kasus kita ini, nilai NR-Stress=0.037 atau 3.7% dan termasuk excellent.
Tucker coefficient of congruence
Coba kita telaah namanya: multidimensional scaling. Kita memang hanya menggunakan aspek input similarity. Namun, kita perlu memahami bahwa persepsi similarity tersebut didasarkan pada berbagai aspek yang tidak terinci. Sama saja kala kita tanya seorang bapak: “Di antara empat anakmu itu, anak nomor berapa yang paling mirip dengan anda? Misalnya bapak itu menjawab: “Anak nomor empat.” Tentu, jawaban bapak itu didasarkan pada berbagai aspek, yang jumlahnya bisa puluhan, seperti: bentuk hidung, warna rambut, postur tubuh, kepatuhan, kepintaran, religiusitas, hobi, prestasi, dan lain-lain. Namun, waktu memberi jawaban, bapak tadi tidak perlu merinci alasan-alasannya.
Demikian pula perbandingan merek dalam kasus ini, kita harus percaya bahwa kesamaan didasarkan pada berbagai aspek. Kemudian, berbagai aspek hipothetik tersebut digabung ke dalam sejumlah dimensi, yang mirip dengan “faktor” dalam analisis faktor. Berapa jumlah “faktor” atau dimensi yang diekstrak? SPSS secara default akan menghasilkan dua dimensi. Namun pada dasarnya, jumlah dimensi dapat diminta satu, dua, tiga, empat, bahkan lebih. Namun, kalau tujuannya adalah menghasilkan peta persepsi, maka jumlah dimensi yang dapat digambarkan adalah satu sampai tiga.
Pada kesempatan ini kita menggunakan dua dimensi. Kedua dimensi itu dapat diperoleh dengan hanya menggunakan satu responden (disebut one sample oleh SPSS) atau lebih dari satu responden (disebut multiple sample oleh SPSS) (Catatan: Seperti telah dijelaskan, aspek one sample ini adalah salah satu kelebihan MDS. Umumnya teknik-teknik statistik yang lain, seperti regresi, analisis faktor, analisis diskriminan, dan lain-lain, menggunakan banyak responden).
Nah, apabila kita menggunakan multisample, nilai Tucker coefficient of congruence (TCC) menyatakan kesamaan atau korelasi antar faktor dari sampel-sampel yang kita gunakan. Oh ya, dalam MDS multisample, data seorang responden dianggap satu sampel. Otomatis, kalau kita menggunakan satu responden, TCC tidak perlu diinterpretasi, walaupun kita temukan pada output.
Nilai TCC dalam kisaran 0,85–0,90 dianggap wajar. Nilai 0.90 sampai 0.94 dianggap tinggi. Nilai 0.95 atau lebih tinggi dianggap sama atau identik. Pada kasus kita ini, dengan TCC=0.98, kesamaan atau korelasi kedua dimensi yang dihasilkan dari kelima sampel adalah identik. Artinya, MDS dari kelima responden adalah identik.
Dispersion Accounted For (DAF)
Dispersion Accounted For (DAF) digunakan untuk mengevaluasi kesesuaian peta persepsi dengan data sumbernya. DAF diperoleh dari NR-Stress dengan rumus: DAF = 1 – NRStress. Dengan demikian, DAF dapat berkisar dari 0 hingga 1. Semakin tinggi nilai DAF, kecocokan model (model fit) semakin baik. Pada model kita, DAF=0.96311. Artinya model baik karena angka ini mendekati 1. Lagi pula, kalau menurut NRStress model MDS adalah good-fit, maka DAF seharus menunjukkan hasil yang sama.
Perceptual Map
Final Coordinates
Out ini berisikan posisi setiap merek (x, y) dalam diagram kartesius. Lihat gambar yang digambar secara manual berdasarkan final coordinate. Hasilnya sama dengan perceptual map yang dberikan oleh SPSS.
| Dimension | ||
| 1 | 2 | |
| Estea | -.565 | -.329 |
| Fresh_Tea | -.541 | .075 |
| Fruit_Tea | .594 | -.516 |
| Lipton | .663 | .075 |
| Sosro | .152 | .708 |
| Tekita | -.303 | -.013 |
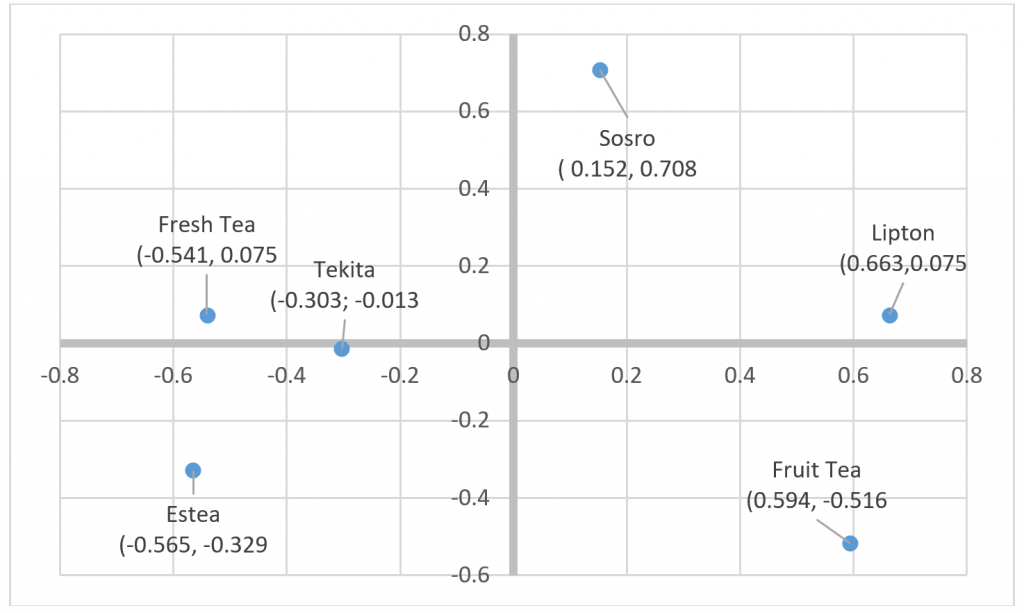
Gambar 1. Perceptual Map dalam Diagram Kartesius berdasarkan Final Coordinates

Gambar 2. Perceptual map output SPSS. Keterangan: Gambar diedit dengan SPSS untuk memperindah tampilan
Mana bersaing paling dekat mana?
Pertanyaan ini dapat dijawab dengan menggunakan perceptual map dan data distances. Secara visual dalam perceptual map terlihat bahwa merek yang posisinya paling berdekatan adalah Fresh Tea dan Tekita. Kedua merek inilah yang bersaing paling dekat. Kesimpulan ini diperkuat oleh data distance, di mana distance paling rendah adalah antar kedua merek, yaitu 0.253. Distance paling tinggi adalah antara Sosro dan Lipton, yaitu 1.302. Berarti kedua merek inilah yang paling tidak bersaing.
| Distances | ||||||
| Estea | Fresh_Tea | Fruit_Tea | Lipton | Sosro | Tekita | |
| Estea | .000 | |||||
| Fresh_Tea | .405 | .000 | ||||
| Fruit_Tea | 1.174 | 1.280 | .000 | |||
| Lipton | 1.293 | 1.204 | .595 | .000 | ||
| Sosro | 1.261 | .939 | 1.302 | .814 | .000 | |
| Tekita | .411 | .253 | 1.029 | .970 | .853 | .000 |
Perlu diketahui bahwa distance dimaksud adalah jarak dalam diagram Kartesius. Jarak ini dapat dihitung secara manual karena ada rumusnya. Silakan dicari rumusnya apabila dibutuhkan pembuktian output SPSS melalui perhitungan manual.
Memberi Nama Dimensi
Apa nama dimensi kesatu dan kedua? Dengan kata lain, berdasarkan apa peta persepsi tersebut dibentuk? Kita bisa menjawab kedua pertanyaan ini dengan memberi nama dimensi kesatu dan kedua. Pemberian nama dilakukan melalui pertimbangan (judgment) berdasarkan posisi setiap merek. Mari kita perhatikan Gambar 1 (Catatan: Gambar 1 dan Gambar 2 sama, namun Gambar 1 lebih mudah dilihat karena diberi sumbu).
Apabila berpatokan ke Sumbu X, Tekita, Fresh Tea dan Estea ada disebelah kiri, sedangkan Sosor, Lipton, dan Fruit Tea ada di sebelah kanan. Apa kira-kira dimensi yang membuat perbedaan demikian? Katakanlah rasa manis, di mana semakin ke kiri, rasanya lebih manis, semakin ke kanan, rasa manis berkurang.
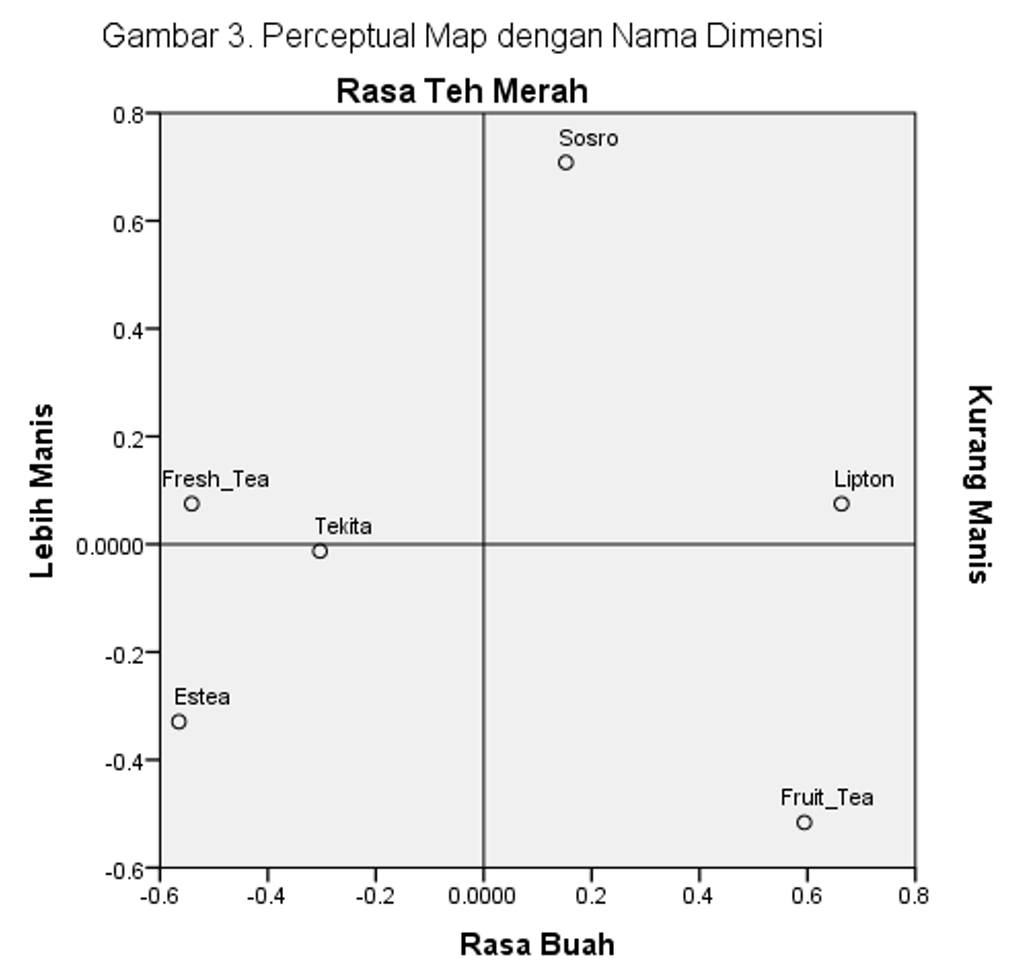
Apabila berpatokan ke sumbu Y, maka Sosro berada di bagian atas dan Fruit Tea pada ujung bawah sumbu. Sebagaimana diketahui, Sosro adalah diposisikan teh merah klasik sedangkan Fruit Tea, sesuai namanya adalah teh rasa buah. Karena itu, kita bisa menamakan sumbu Y sebagai rasa teh, di mana semakin ke atas, semakin terasa sebagai teh merah dan semakin ke bawah semakin terasa sebagai rasa buah, seperti terlihat pada Gambar 3.
One Matrix Source
1. Download data dari sini. Buka data di SPSS. Tampil datanya seperti ini.
2. Pada menu utama SPSS, pilih analyze, lalu Scale, setelah itu klik multimension scaling (PROXSCALL). Dalam SPSS, ada dua pilihan MDS. Selain PROXSCALL, satu lagi adalah ASCALL. Untuk bentuk matrik seperti di atas, PROXSCALL memberikan hasil lebih baik karena ada koordinat merek-merek mudah di-copy. Jadi, kita pilih program ini.
3. Pada kotak dialog yang muncul, pilih: The data are proximities, One matrix source, Proximities are in a matrix across column, lalu klik Define.
4. Pada kotak dialog yang muncul, masukkan semua merek pada sel proximities.
5. Klik Model. Pada langkah ini:
- Pastikan Shape adalah Lower-triangular matrix. Parena pola data kita dapat membentuk dua segitiga, yaitu di atas dan di bawah diagonal. Data di atas mengambil pola setiga bagian bawah.
- Pastikan Proximities adalah Dissimilarities. Bukankah judul menyatakan bahwa perceptual map yang kita bangun adalah berbasis Similarity? Betul. Namun, SPSS menginterpretasi bahwa semakin tinggi angka, semakin tinggi nilainya. Nah, pada data kita, semakin rendah angka, semakin tinggi similarity (kesamaan). Semakin tinggi angka, semakin tinggi dissimilarity (perbedaan).
- Pastikan Proximities transformation adalah Ratio.
6. Klik Plot dan tandai Common space.
7. Klik Output dan tandai Comonspace coordinates, multiple stress source, dan Distances.
8. Klik OK. Sekarang kita interpretasi hasilnya.
Output
NRStress=0.03665 dan D.A.F=0.96335, artinya model adalah Good fit. Tucker coefficient of congruence tidak perlu diinterpretasi karena sumber kita hanya satu matrix. SPSS memberikan final coordinates, commonspace, dan distances. Cara menginterpretasinya sama seperti kasus multiple source matrix di atas. Silakan dicoba sendiri.
Single Matrix versus Multiple Matrix Source
Berbicara mana yang dipakai tergantung kebutuhan. Sebagaimana diketahui, persepsi ada yang bersifat individual, ada pula yang bersifat publik. Apabila meneliti persepsi individual, misalnya posisi merek di benak individu, gunakan one matrix source. Apabila menginvestigasi persepsi sejumlah orang, gunakan multiple matrix sources.
- MDS Non-Atribut berbasis Skala Numerik
- MDS dengan Anchor Point Clustering Method
- MDS Similarity berbasis Atribut
- MDS with Comparative-based Preference
- MDS with Attitude-based Preference
REFERENSI
Borg, I., Groenen, P. (1997). MDS fit measures, their relations, and some algorithms. In: Modern Multidimensional Scaling. Springer Series in Statistics. Springer, New York, NY. https://doi.org/10.1007/978-1-4757-2711-1_11
Dugard, P., Todman, J., & Staines, H. (2010). Approaching Multivariate Analysis. A Practical Introduction. Second Edition. Routledge: New York. This text has example analyses using SPSS.