Last updated on June 13, 2023 by Bilson Simamora
Tentang persepsi kualitas, sebagian pemerhati membedakan perceived quality dan perception of quality. Menurut mereka yang membedakan, perceived quality adalah kualitas yang disimpulkan melalui pengalaman. Menurut Schmitt (1999), pengalaman konsumsi terdiri dari komponen-komponen sense, feel, think, act, dan relate. Kalau kita ambil komponen yang relevan, persepsi kualitas adalah kesimpulan tentang kualitas setelah produk disentuh, dicium, dirasakan, dan digunakan konsumen. Sedangkan perception of quality adalah kesimpulan tentang kualitas suatu produk yang belum dialami, yang dibuat berdasarkan pengolahan informasi. Tentu, sulit memisahkan perception of quality dan perceived quality, sebab, persepsi kita tentang kualitas, tidak bisa diverifikasi secara pasti apakah berbasis informasi ataukah pengalaman, keduanya bercampur (blended). Dalam tulisan ini, keduanya dianggap sama saja.
Persepsi kualitas dapat diukur melalui pendekatan total, misalnya:
Menurut anda, mobil Nissan Livina:
Bagus 1 2 3 4 5 6 7 Buruk
Persepsi kualitas bisa pula diukur melalui pendekatan atribut. Di bawah ini kita buat pernyataan-pernyataan berbasis atribut dengan semantic differential scale.
Berikan nilai merek mobil A ini pada setiap atribut.
Tampilan luar
Cantik Ο Ο Ο Ο Ο Ο Ο Jelek
Interior
Menyenangkan Ο Ο Ο Ο Ο Ο Ο Membosankan
Fitur
Minim Ο Ο Ο Ο Ο Ο Ο Berlimpah
Power
Kecil Ο Ο Ο Ο Ο Ο Ο Besar
Kenyamanan
Nyaman Ο Ο Ο Ο Ο Ο Ο Tidak nyaman
Harga
Mahal Ο Ο Ο Ο Ο Ο Ο Sedikit
Spare part
Banyak Ο Ο Ο Ο Ο Ο Ο Sedikit
Merek
Memalukan Ο Ο Ο Ο Ο Ο Ο Membanggakan
Pada contoh di bawah ini, responden diminta untuk menilai lima merek yang dianggap satu sama lain. Hasilnya disajikan pada tabel di bawah. Angka pada tabel ini adalah 1 (tinggi) sampai 7 (rendah). Penentuannya disesuaikan dengan metoda MDS yang digunakan.
Tabel 1. Data
| Mobil A | Mobil B | Mobil C | Mobil D | Mobil E | |
| Tampilan_luar | 7 | 1 | 2 | 3 | 1 |
| Interior | 4 | 3 | 1 | 2 | 1 |
| Fitur | 3 | 3 | 3 | 2 | 1 |
| Power | 6 | 4 | 1 | 2 | 5 |
| Kenyamanan | 4 | 2 | 5 | 3 | 2 |
| Harga | 1 | 2 | 7 | 2 | 1 |
| Spare_part | 5 | 3 | 7 | 4 | 6 |
| Merek | 7 | 3 | 7 | 2 | 6 |
Sekarang kita mau buat peta persepsi kelima merek di atas. Download datanya dari sini, simpan pada folder yang mudah anda cari. Setelah data dibuka dengan SPSS, lakukan prosedur berikut ini:
- Analyze>Scale>Multidimension Scale (ASCALL). Keterangan: SPSS memberikan tiga aplikasi MDS, yaitu PREFSCAL, PROXSCAL dan ALSCAL. Kita menggunakan aplikasi sesuai kebutuhan.
- Pindahkan Merek A, Merek B, Merek C, Merek D, dan Merek E ke ruang Variables
- Pastikan Data are distance. Keterangan: Distance adalah jarak merek dengan atribut. Semakin besar angkanya, semakin jauh jarak merek atau semakin tidak baik merek pada atribut tersebut. Penentuan ini kita lakukan berdasarkan kebutuhan aplikasi ALSCAL.
- Klik tombol Shape dan pilih Rectanguler. Sel number of rows dapat dikosongkan atau diisi sesuai jumlah atribut.
- Klik Model. Pastikan Level of measurement adalah Interval, Conditionality adalah Row dan Scaling Model adalah Euclidean distance. Keterangan: Pilihan interval didasarkan pada jenis data yang dihasilkan oleh semantic differential scale. Conditionality membatasi mana yang dapat dibandingkan. Pada kasus ini, yang kita bandingkan adalah merek-merek mobil yang diletakkan pada kolom. Baris berisikan atribut. Kita tidak membuat perbandingan antar atribut yang diletakkan pada baris (row). Jadi, pilihan Row pada menu Conditionality adalah untuk memerintahkan program tidak melakukan perbandingan antar baris.
- Klik Option>Group plots.
- Klik OK
Hasilnya adalah sebagai berikut.
Pertama-tama, kita lihat apakah model kita bagus ataukah buruk berdarakan S-Stress dan RSQ. Stress mengindikasikan proporsi varian perbedaan (disparity) yang tidak dijelaskan oleh model. Semakin rendah stress, semakin baik model MDS yang dihasilkan”. Pertanyaannya, sampai nilai berapa stress masih mengindikasikan model yang baik? Untuk menjawab pertanyaan ini, Dugard et al. (2010) memberi ketentuan seperti di bawah ini.
| 100 x Stress (Percent) | Goodness of Fit |
| 20% or above | Poor |
| 10%-19.9% | Fair |
| 5%-9.9% | Good |
| 2.5%-4.9% | Excellent |
| 0%-2.4% | Near Perfect |
Pada output di atas, ada tiga nilai stress, yaitu Normalized Raw Stress, Stress I, Stress II, dan S-Stress. Yang menjadi perhatian kita adalah S-Stress dan Normalized Raw Stress. S-stress dihitung berdasarkan squared distance, sedangkan Normalized Raw Stress (NRStress) dihitung berdasarkan distances. Yang terbaik di antara keduanya adalah NRStress (Borg & Groenen, 1997). ALSCAL hanya memberikan nilai Stress dan S-Stress.
Pada kasus kita, Stress=0.247 atau 24.7% dan termasuk poor (buruk). Pada iterasi ke-30, S-Stress=0,153 atau 15,5% dan termasuk fair (cukup bagus). Nilai RSQ adalah 0.951 atau 95.1%. Artinya, kemampuan model menjelaskan data asli adalah 95.1%. Melalui judgment dapat kita simpulkan bahwa model memiliki kualitas cukup baik.
Berdasarkan output ALSCAL, kita dapat membuat tabel koordinat merek dan atribut seperti di bawah ini. Peta persepsi didasarkan pada data koordinat tersebut.
Tabel 2. Koordinat Merek
| No. | Merek | Dimensi I | Dimensi II |
| 1 | Merek_A | 1,3048 | -1,5316 |
| 2 | Merek_B | ,8497 | ,4620 |
| 3 | Merek_C | -2,0710 | ,1613 |
| 4 | Merek_D | -,0272 | ,7865 |
| 5 | Merek_E | -,1298 | -1,3304 |
Tabel 3. Koordinat Atribut
| No. | Atribut | Dimensi I | Dimensi II |
| 1 | Tampilan_luar | -,7408 | -,0451 |
| 2 | Interior | -1,0398 | -,4624 |
| 3 | Fitur | -,4313 | -,6943 |
| 4 | Power | -1,2627 | ,8690 |
| 5 | Kenyamanan | ,0363 | -,3664 |
| 6 | Harga | ,9484 | -,6794 |
| 7 | Spare_part | 1,8401 | 1,3179 |
| 8 | Merek | ,7233 | 1,5129 |
Berdasarkan data Tabel 2 dan Tabel 3, peta persepsi yang kita peroleh adalah sebagai berikut.

Pada gambar peta persepsi di atas, nama atribut tidak diberikan. Program hanya memberi nomor baris. Tentu kita tahu nama setiap baris dari data SPSS maupun Tabel 3 di atas.
Kedekatan setiap merek dan atribut dapat kita lihat dalam MDS. Pertama-tama, tarik garis yang melalui titik yang ditempati baris dan titik pusat, namanya garis ideal. Kemudian, buat garis tegak lurus antara merek dengan garis ideal.
Di bawah ini diberikan satu contoh, yaitu garis ideal merek. Apabila diamati secara visual, merek D adalah yang paling dekat dengan garis ideal merek. Yang terjauh adalah merek C dan Merek A. Hasil ini konsisten dengan data pada Tabel 1.

Kita dapat menghitungkan jarak setiap merek dengan garis ideal dengan menggunakan rumus matematika. Karena data yang dimasukkan menyatakan semakin besar angka semakin tinggi persepsi kualitas (misalnya 7 lebih tinggi dari 1), maka dalam gambar di atas, semakin jauh jarak, semakin bagis posisi merek pada atribut itu. Untuk itu, pertama-tama, kita buat dulu persamaan garis ideal. Setelah itu, kita cari jarak tegak lurus antara titik koordinat merek dengan persamaan garis ideal. Namun, tujuan sesungguhnya MDS adalah adalah membuat peta persepsi merek-merek yang saling bersaing atau berada dalam frame of reference yang sama. Pengertian frame of reference dapat ditemukan di sini.
Cara untuk mengkukur jarak tegak lurus sebuah titik dengan garis lurus:
- Buat dulu persamaan garis lurus.
- Hitung jarak tegak lurus dengan rumus ini:
 Di mana, DP=jarak tegak lurus yang dicari, X=ordinat titik, dan Y = absis titik A, B, dan C adalah koefisien garis lurus (dalam hal ini kurva keinginan pasar).Koordinat row 8 adalah (0.7233, 1.5129). Garis yang melalui row 8 dan titik (0.0) mau kita buat dalam persamaan liniear: Y=a + bX + C. Untuk setiap persamaan yang melewati titik O, maka nilai a=0 dan c=0. Jadi, yang perlu dicari adalah nilai b, yaitu:
Di mana, DP=jarak tegak lurus yang dicari, X=ordinat titik, dan Y = absis titik A, B, dan C adalah koefisien garis lurus (dalam hal ini kurva keinginan pasar).Koordinat row 8 adalah (0.7233, 1.5129). Garis yang melalui row 8 dan titik (0.0) mau kita buat dalam persamaan liniear: Y=a + bX + C. Untuk setiap persamaan yang melewati titik O, maka nilai a=0 dan c=0. Jadi, yang perlu dicari adalah nilai b, yaitu:
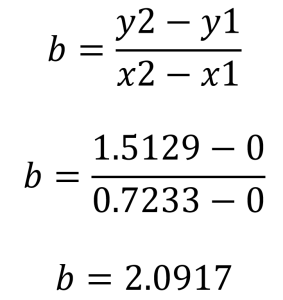
Persamaan standar: Y=a + bX + C dapat dijadikan ke dalam bentuk: Y-bX-C=0
Jadi, Y=2.091X –>Y – 2.091X – 0=0
Dari persamaan ini, untuk keperluan mencari jarak diperoleh: a=1, b=-2.0917, c=0
Untuk merek A, koordinatnya adalah (1.3048, -1.5316) atau X=1.3048 dan Y=-1.5348). Masukkan nilai ini ke rumus di atas:

Sekali lagi, karena data yang kita masukkan adalah perceived quality, di mana semakin besar nilai PQ semakin bagus sebuah merek, maka semakin besar nilai DP juga menyatakan kualitas sebuah merek pada garis itu.