Last updated on December 6, 2023 by Bilson Simamora
Pendahuluan | Tujuan Analisis Faktor | Variabel dan Sampel | Teknik Ekstraksi | Principal Component Analysis | Correlation Matrix | KMO and Barlet Test of Sphericity | Anti Image Matrices | Total Variance Explained | Scree Plot | Jumlah Faktor yang Diekstrak | Memberi Nama Faktor | Common Factor Analysis | Confirmatory Factor Analysis | Keterbatasan Analisis Faktor
Pendahuluan
Analisis faktor menganalisis kombinasi linier antar variabel. Analisis faktor tergolong interdependence technic, sebagaimana analisis klaster dan multidimension scaling. Status semua variabel sama, tidak ada variabel independen dan dependen, sebagaimana pada dependence technics, seperti regresi.
Apabila dalam sejumlah besar variabel terdapat multikolinearitas, dapatlah kita mencurigai adanya sejumlah faktor dalam data kita. Faktor disebut juga variabel laten. Konstruk adalah variabel laten yang sudah dinobatkan menjadi konsep. Analisis faktor dapat kita gunakan untuk mencari konstruk baru dari sejumlah variabel. Sehubungan dengan itu, dalam pembelajaran kali ini, terdapat pembahasan tentang ‘memberikan nama faktor’ yang analog dengan menobatkan faktor menjadi konstruk (pengertian konstruk dijelaskan di sini).
Pekerjaan, pendapatan, dan kekayaan, misalnya, tentulah berkorelasi satu sama lain. Pekerjaan yang bagus akan menghasilkan pendapatan yang tinggi, selanjutnya kekayaan yang lebih tinggi. Apakah tidak lebih baik ketiga variabel diwakilkan satu variabel saja? Jawabannya ya. Dalam stepwise regression, dari ketiga variabel tersebut, kita akan mencari salah satu variabel yang paling mewakili. Sedangkan dalam analisis faktor, kita tidak memilih salah satu, akan tetapi mencari variabel baru (yang dinamakan faktor) untuk mewakili ketiganya, lengkap dengan skor baru.
Tanpa analisis faktor pun, kita dapat mengelompokkan ketiga variabel di atas sebagai kelas sosial karena teori mengatakan demikian. Namun, pengakuan teori tidaklah cukup – sekalipun hasil analisis faktor tidak boleh melawan teori – masih diperlukan bukti empiris untuk mengetahui seberapa yakin kita dengan kesimpulan yang kita buat.
Tujuan Analisis Faktor
Mengonfirmasi variabel-variabel pengamatan suatu konstruk
Dalam sebuah penelitian, sering kita mengoperasionalkan suatu konstruk atau sub-konstruk ke dalam beberapa variabel pengamatan. Pengertian konstruk, sub-konstruk (dimensi) dan variabel dapat dibaca di sini.
Di bawah ini ditampilkan konstruk tujuan berprestasi (achievement goals) yang lazim dipakai dalam dunia pendidikan. Konstruk ini terdiri dari empat dimensi, yaitu mastery approach, mastery avoidance, performance approach, dan performance avoidance. Dengan analisis faktor konfirmatori kita dapat memeriksa apakah setiap variabel pengamatan tergabung ke dalam dimensinya (disebut analisis faktor tingkat pertama) dan apakah setiap dimensi tergabung pada konstruknya (disebut analisis faktor tingkat kedua). Analisis faktor demikian disebut analisis faktor konfirmatori (confirmatory factor analysis). Analisis ini dapat juga dipakai sebagai analisis validitas dalam riset.
Tabel 1. Contoh Konstruk, Dimensi dan Variabel
| Achievement Goals |
| Mastery Approach |
| My aim is to completely master the material presented in this class |
| I am striving to understand the content of this course as thoroughly as possible |
| My goal is to learn as much as possible |
| Mastery Avoidance |
| My aim is to avoid learning less than I possibly could |
| My goal is to avoid learning less than it is possible to learn |
| I am striving to avoid an incomplete understanding of the course material |
| Performance Approach |
| I am striving to do well compared to other students |
| My aim is to perform relatively well relative to other students |
| “My goal is to perform better than the other students |
| Performance Avoidance |
| My goal is to avoid performing poorly compared to other students |
| I am striving to avoid performing worse than other students |
| My aim is to avoid doing worse than other students |
| Sumber: Eliot, A.J., & McGregor, H.A. (2001). A 2 × 2 achievement goal framework. Journal of Personality and Social Psychology, 80(3), 501–519. DOI: 10.1037/0022-3514.80.3.501. |
Mengidentifikasi Struktur Hubungan Antar Variabel
Analisis faktor dapat digunakan untuk mengidentifikasi struktur hubungan antar variabel ataupun antar responden. Katakanlah kita punya 10 variabel. Dengan melihat korelasi antar variabel, kita dapat mengetahui dimensi-dimensi laten yang mendasari. Dalam contoh terdahulu, kita memang menyatukan variabel-variabel ‘pekerjaan, pendapatan dan kekayaan’ menjadi kelas sosial. Namun, tidak selalu mudah menemukan dimensi-dimensi laten kalau belum ada teori yang melandasinya. Analisis faktor dapat menolong kita untuk menemukan dimensi-dimensi yang mendasari sejumlah variabel.
Kalau tujuan analisis faktor adalah untuk mencari dimensi-dimensi laten yang mewakili variabe-variabel, maka analisis faktor yang kita lakukan disebut exploratory factor analysis.
Analisis faktor juga dapat digunakan untuk mencari korelasi antar responden. Dengan kata lain, dengan analisis faktor, tepatnya analisis faktor Q (Q factor analysis), kita dapat mengelompokkan responden berdasarkan kesamaan-kesamaan karakteristik yang dimilikinya. Segmentasi responden dengan analisis faktor Q jarang dilakukan. Untuk tujuan tersebut, umumnya para peneliti menggunakan analisis klaster.
Mengurangi Variabel
Adakalanya jumlah responden yang kita miliki tidak mencukupi. Sebagai contoh, dalam analisis SEM terdapat ketentuan bahwa jumlah responden minimal adalah lima kali jumlah variabel pengamatan (Hair, et al. 2014; Wijanto, 2008). Katakanlah kita memiliki 200 responden dan variabel pengamatan berjumlah 60. Berarti ketentuan tersebut belum terpenuhi. Jalan keluarnya adalah mengurangi jumlah variabel pengamatan. Analisis faktor dapat digunakan untuk keperluan tersebut.
Ada tiga cara mengurangi variabel, pertama menggunakan ‘faktor’ yang dihasilkan, kedua memakai surrgogate variables dan ketiga, menggunakan summated scales. Dengan analisis faktor, kita dapat menemukan faktor-faktor (disebut juga dimensi ataupun komponen) yang mewakili variabel-variabel asli. Katakanlah kita temukan tiga faktor. Ketiga faktor ini dapat dijadikan variabel baru yang mewakili kesepuluh variabel asli, dengan catatan informasi yang hilang diminimalkan. Bisa pula beberapa variabel diwakili faktor, sementara variabel lain tetap dalam bentuk aslinya. Ini merupakan tujuan paling umum. Dalam banyak penelitian, kita tidak tahu variabel mana dengan variabel mana yang bisa dipertautkan, sebelum analisis faktor dilakukan.
Surrogate variable adalah adalah variabel yang berhubungan paling erat dengan faktor. Misalkan kita memiliki enam variabel pengamatan. Setelah dilakukan analisis faktor, faktor loading dari X1 sampai X6 adalah: 0.654, 0.457, 0.870, 0.786, 0.721 dan 0.612. Dengan demikian, X3 adalah surrogate variable.
Summated scale (penjelasan tentang skala pengukuran boleh dilihat di sini) berarti menggunakan hasil penjumlahan skor semua variabel pengamatan sebagai skor variabel baru. Cara ini bisa dilakukan apabila dipastikan variable-variabel pengamatan yang digunakan memang tergabung pada satu faktor.
Menggunakan Analisis Faktor dengan Teknik Analisis Lain
Dengan kemampuan dasar menganalisis korelasi antar variabel, mencari dimensi-dimensi yang mendasari serta meringkas data, analisis faktor dapat dikombinasikan dengan teknik analisis lain dalam riset pemasaran maupun dalam displin ilmu lainnya. Karena itu, Hair et. al. (2014) mengatakan sebagian ahli menganggap analisis faktor sebagai bagian dari riset eksploratori, sekali pun sebenarnya teknik ini juga dapat dipakai untuk tujuan konfirmatori.
Untuk teknik apa saja analisis faktor dapat digunakan? Sebenarnya tergantung pada apakah teknik lain tersebut memer-lukan fungsi dasar analisis faktor.
Sekiranya kita memiliki 15 variabel, lalu ingin menganalisis image suatu merek dengan teknik sarang laba-laba yang memerlukan delapan dimensi. Kelima belas variabel asli harus dipadatkan terlebih dahulu menjadi delapan variabel, tentunya dengan analisis faktor.
Contoh lain begini. Sebuah merek memiliki 12 appeals (daya tarik atau reasons to buy). Kalau dalam iklan semuanya diajukan sekaligus, penetrasi pesan ke dalam otak konsumen akan kurang dalam. Pada sisi lain, perusahaan tidak mau mengurangi jumlah appeals yang ditawarkan menjadi dua, tiga dan seterusnya, maunya semua appeals terekspos dalam iklan. Analisis faktor dapat mengakomodasi keinginan perusahaan sekaligus mempertajam penetrasi pesan. Caranya, dengan memadatkan keduabelas appeals tersebut menjadi beberapa faktor saja. Itulah yang diekspos dalam iklan, setelah melalui proses kreatif.
Bagi yang terbiasa dengan regresi ganda (multiple regression), multikolinearitas – yaitu adanya korelasi antar variabel independen- tentu tidak disukai. Multikolinearitas dapat dideteksi melalui analisis faktor. Melalui analisis faktor, dengan mudah kita mengetahui variabel mana saja yang berkorelasi.
Variabel dan Sampel Yang Dilibatkan
Untuk analisis data yang dibutuhkan adalah data metrik. Memang analisis faktor juga dapat menggunakan variabel dummy, misalnya dengan metoda Boolen, namun jarang dilakukan.
Sekali pun peneliti memerlukan jumlah variabel yang optimal untuk setiap faktor, variabel yang dilibatkan dalam analisis faktor minimal lima (Hair et al., 2014). Memang SPSS menerima dua variabel, akan tetapi, janganlah menganggap bahwa hasil analisis faktor sudah menjawab segala permasalahan walaupun jumlah variabel sedikit (misalnya dua). Dalam analisis faktor, judgment tetap diperlukan agar hasilnya baik. Analisis faktor hanya menghasilkan angka. Sekiranya angka-angka tersebut kita masukkan sembarang, analisis faktor tetap saja melakukan tugasnya, namun hasilnya tentu sembarangan juga.
Tidak ada ukuran sampel minimal yang diterima dalam analisis faktor. Memang, semakin besar ukuran sampel, analisis faktor semakin akurat. Sebaiknya memang ukuran sampel 100 atau lebih, dan janganlah melakukan analisis faktor kalau ukuran sampel kurang dari 50. Akan tetapi ketentuan ini tidak mutlak.
Sebagai aturan umum, jumlah responden minimal (kadang-kadang juga disebut kasus atau observasi, penulis) adalah lima kali jumlah variabel. Jadi, kalau ada lima variabel, maka jumlah responden minimal adalah 25 orang. Apakah 25 responden cukup? Walaupun memenuhi sesuai jumlah variabel, namun untuk hasil yang lebih baik, gunakan ukuran sampel yang lebih besar, misalnya 150 responden. Dari pada menggunakan rasio satu (variabel) dibanding lima (responden), lebih baik lagi kalau rasionya adalah satu banding sepuluh. Bahkan, ada peneliti yang menginginkan perbandingan 1: 20 (Hair et al., 2014). Namun, jumlah akhir responden tetap dipertimbangkan. Sekali lagi, ketentuannya adalah hasil analisis faktor akan lebih baik jika menggunakan sampel berukuran besar.
Teknik Ekstraksi Analisis Faktor
Analisis multivariat adalah displin ilmu yang sangat dinamis. Banyak metoda yang dimunculkan para ahli. Seorang yang tergolong ahli sekalipun bisa saja tidak menguasai semua metoda karena metoda yang berkembang terus. Dalam SPSS, misalnya terdapat enam metoda, yaitu principal component analysis, principal axis factoring, weigthed least square atau generalized least square, maximum likelihood, dan alpha factoring. Berikut penjelasan singkatnya.
Principal component analysis
Dipakai apabila kita ingin mengetahui variabel laten dari sejumlah variabel pengamatan. Misalnya, kita memiliki 15 variabel pengamatan. Kemudian kita ingin mengetahui berapakah variabel laten yang mendasari variabel-variabel tersebut? Dalam proses ini, PCA memperhitungkan unique variance dan common variance. Sebelumnya, kita perlu ketahui bahwa ada tiga komponen variance sebuah variabel. Pertama, common variance, yaitu variance suatu variabel yang juga dimiliki variabel-variabel lain (variance in a variable that is shared with all other variables). Kedua, specific variance, yaitu variance yang dimiliki hanya oleh variabel itu. Ketiga, error variance, yaitu varian sebuah varibel yang ditimbulkan oleh kesalahan pengukuran, kesalahan alat ukur ataupun kesalahan pemilihan sampel. Principal component analysis (PCA) menggunakan total varian, yang mencakup ketiga komponen varian itu dalam analisis. Namun, metoda ini berusaha menghasilkan faktor yang memiliki specific variance dan error variance yang paling kecil. Kalau ada beberapa faktor yang dihasilkan dari sejumlah variabel, misalkan tiga faktor dari 10 variabel, maka faktor pertama yang dibentuk adalah yang memiliki common variance terbesar, sekaligus specific dan error variance terkecil.
PCA bertujuan untuk mengetahui jumlah faktor minimal yang dapat diekstrak. Namun, apabila memilih metoda ini, peneliti harus yakin bahwa common variance lebih besar dari specific dan error variance.
Principal Axis Factoring
Disebut juga common factor analysis, bertujuan untuk menemukan sesedikit mungkin faktor berdasarkan common variance atau korelasi sejumlah faktor. Common factor analysis mengekstrak faktor hanya berdasarkan common variance. Metoda ini dapat dipakai apabila tujuan utama peneliti adalah untuk mengetahui dimensi-dimensi laten atau konstruk yang mendasari variabel-variabel asli. Memang, dengan metoda ini, jumlah faktor tetap diekstrak, akan tetapi metoda ini lebih kuat dalam mengungkap dimensi-dimensi laten yang melandasi variabel-variabel asli. Sebagai tambahan, metoda ini juga dapat dipakai kalau peneliti tidak mengetahui specific dan error variance, sehingga mau diabaikan saja dalam analisis.
Kalau mau menggunakan common factor analysis, peneliti perlu mengetahui beberapa kelemahan, seperti dikemukakan Hair et al. (2014). Pertama, faktor indeterminancy, yaitu setiap responden dapat memiliki beberapa skor yang berbeda yang dihasilkan dari model yang dihasilkan. Kedua, communalities tidak selalu dapat dicari, kalaupun bisa, hasilnya dapat invalid (lebih besar dari 1). Dengan adanya kelemahan-kelemahan tersebut, pemakaian principal component analysis lebih luas. Sekalipun demikian, pemakaian kedua metoda sering menghasilkan kesimpulan yang sama.
PCA dan PAF adalah dua metoda yang paling banyak digunakan. Metoda-metoda lain tetapi jarang digunakan adalah weighted least square, maximum likelihood, dan alpha factoring.
Maximum likelihood adalah prosedur untuk menemukan nilai satu atau lebih parameter dengan harapan likelihood distribution yang diketahui maksimum. Metoda ini bertujuan menemukan factor loading dengan memaksimalkan fungsi unique variances untuk menemukan faktor yang unik pula. Teknik ini memungkinkan peneliti untuk mengukur indeks goodness of fit model, termasuk untuk menguji signifikansi factor loading yang dihasilkan secara statistic, menguji korelasi antar faktor dan juga menghitung confidence interval antar parameter. Teknik ini membutuhkan data berdistribusi normal, kalua tidak, jangan gunakan sama sekali.
Ordinary or Unweighted least squares dimaksudkan untuk meminimalkan residual antara input matriks korelasi dengan matrik korelasi yang dihasilkan faktor-faktor yang dihasilkan. Generalized or Weighted least squares adalah modifikasi atas teknik di atas. Tujuannya juga sama yaitu meminimalkan residual antara input matriks korelasi dengan matrik korelasi yang dihasilkan faktor-faktor yang dihasilkan. Namun, teknik ini memberikan bobot korelasi yang berbeda, di mana korelasi antar variabel yang keunikannya tinggi diberi bobot lebih rendah. Teknik ini digunakan apabila peneliti ingin kesesuaian (fit) faktor dengan unique variables lebih rendah dibanding dengan common variables.
Alpha factoring sesuai untuk teknik analisis faktor yang mengamnggap bahwa yang digunakan merupakan sampel dari populasi variabel yang tentunya jumlahnya lebih banyak. Teknik ini dimaksudkan untuk memaksimalkan reliabilitas alpha faktor-faktor yang dihasilkan.
Principal Component Analysis
Sampai bagian ini, banyak konsep analisis faktor yang belum dijelaskan. Contoh kasus berikut ini, selain menunjukkan bagaimana analisis faktor dilakukan, juga menjelaskan konsep-konsep lain yang perlu diketahui. Penjelasan konsep-konsep tersebut sengaja diberikan bersamaan dengan contoh kasus dengan harapan lebih mudah dimengerti.
Judul penelitian: Faktor-faktor Yang Mempengaruhi Pilihan Konsumen terhadap Sabun Aroma Buah
Dari namanya mudah dimengerti bahwa sabun aroma buah adalah sabun yang aromanya menyerupai buah-buahan. Namun, pengertiannya tidak sesempit itu. Betul aromanyan seperti buah-buahan, akan tetapi kelebihannya bukan hanya itu. Oleh produsennya, sabun ini diklaim juga terbuat dari bahan-bahan alami pilihan.
Persoalan yang menarik bukan terbuat dari apa sabun ini, melainkan faktor-faktor apa yang menarik konsumen membeli sabun ini, mengingat harganya yang lebih mahal dari sabun biasa sekelas Lux, Giv, Camay dan lain-lain. Untuk lebih jelasnya, yang mau diketahui adalah, dimensi-dimensi apa yang melandasi semua alasan konsumen membeli sabun ini. Ada tujuh alasan yang dijadikan sebagai variabel, yaitu: (1) aroma sabun, (2) tekstur (keras atau lembutnya sabun di kulit), (3) kebersihan kulit, (4) kelembutan kulit, (5) kehalusan kulit, (6) desain sabun dan (7) warna sabun. Variabel-variabel tersebut dijadikan menjadi item pertanyaan menggunakan skala numerik sebagai berikut:
1. Aroma ‘sabun aroma buah’ lebih wangi dari sabun biasa:
Sangat setuju 7 6 5 4 3 2 1 Setuju
2. Sabun aroma buah lebih lembut di kulit daripada sabun biasa
Sangat tidak setuju 1 2 3 4 5 6 7 Sangat setuju
3. Sabun aroma buah membersihkan kulit lebih baik dari sabun biasa.
Sangat Setuju 7 6 5 4 3 2 1 Sangat tidak setuju
4. Dibanding dengan sabun biasa, dengan aroma buah, kulit lebih lembut.
Sangat tidak setuju 1 2 3 4 5 6 7 Sangat setuju
5. Kulit lebih halus dengan sabun aroma buah dibanding sabun biasa.
Sangat setuju 7 6 5 4 3 2 1 Setuju
6. Sabun aroma buah didesain lebih menarik dibanding sabun biasa.
Sangat tidak setuju 1 2 3 4 5 6 7 Sangat setuju
7. Sabun aroma buah memiliki warna-warni yang lebih menarik dibanding sabun biasa.
Sangat setuju 7 6 5 4 3 2 1 Setuju
Dengan tujuh variabel, kalau menggunakan rasio 1: 5, mestinya perlu 35 responden. Bahkan responden lebih banyak lagi kalau menggunakan rasio 1: 10, yaitu 70 responden. Hasil pada Tabel 1 yang hanya menggunakan 25 responden dimaksudkan hanya sebagai contoh. Jadi, jangan dulu dipersoalkan apakah dengan responden sebanyak itu hasil analisis faktor optimal ataukah tidak.
Tabel 1. Hasil Penelitian
| Resp. | X1 | X2 | X3 | X4 | X5 | X6 | X7 |
| 1 | 3 | 3 | 5 | 5 | 6 | 2 | 3 |
| 2 | 4 | 3 | 3 | 4 | 5 | 3 | 3 |
| 3 | 4 | 3 | 2 | 2 | 3 | 3 | 4 |
| 4 | 2 | 2 | 3 | 3 | 4 | 2 | 2 |
| 5 | 6 | 5 | 5 | 6 | 5 | 6 | 5 |
| 6 | 5 | 5 | 4 | 3 | 4 | 5 | 4 |
| 7 | 4 | 4 | 5 | 4 | 5 | 5 | 4 |
| 8 | 4 | 5 | 7 | 5 | 6 | 6 | 6 |
| 9 | 5 | 5 | 5 | 4 | 5 | 6 | 5 |
| 10 | 4 | 4 | 4 | 4 | 4 | 5 | 4 |
| 11 | 5 | 5 | 3 | 2 | 4 | 5 | 5 |
| 12 | 6 | 5 | 4 | 3 | 3 | 6 | 5 |
| 13 | 5 | 4 | 5 | 5 | 6 | 4 | 4 |
| 14 | 3 | 4 | 4 | 5 | 5 | 3 | 2 |
| 15 | 4 | 2 | 5 | 6 | 6 | 4 | 3 |
| 16 | 6 | 6 | 3 | 4 | 3 | 7 | 5 |
| 17 | 4 | 4 | 5 | 6 | 5 | 5 | 5 |
| 18 | 3 | 4 | 3 | 4 | 5 | 5 | 6 |
| 19 | 7 | 5 | 3 | 4 | 5 | 4 | 5 |
| 20 | 5 | 4 | 5 | 6 | 6 | 4 | 3 |
| 21 | 5 | 5 | 6 | 7 | 7 | 5 | 6 |
| 22 | 4 | 5 | 4 | 5 | 4 | 4 | 5 |
| 23 | 5 | 6 | 2 | 2 | 2 | 5 | 6 |
| 24 | 6 | 5 | 5 | 5 | 4 | 5 | 6 |
| 25 | 4 | 6 | 2 | 2 | 4 | 5 | 6 |
Prosedur
- Dari menu utama, pilih analyze, kemudian data reduction, lalu klik factor analysis.
- Highlight semua variabel, lalu masukkan ke dalam ruang variabels.
- Klik menu descriptive, akan tampak kotak dialog seperti di bawah ini, lalu beri tanda dengan meng-‘klik’ pilihan-pilihan univariate descriptive, initial solution, coefficient, dan KMO and Barlett test of Sphericity.
- Klik menu descriptive. Lalu, pada kotak dialog yang ditampilkan, pilih principal components, lalu kembali dengan meng-‘klik’ continue.
- Klik menu rotation. Tandai pilihan-pilihan varimax, rotated solutions dan loading plot(s).
Hasil dan Interpretasi
Descriptive Analysis
Setiap cerita biasanya dimulai dari hal-hal ringan. Analisis faktor juga demikian. Analisis deskriptif tidak khas analisis faktor, akan tetapi bersifat umum pada setiap penelitian.
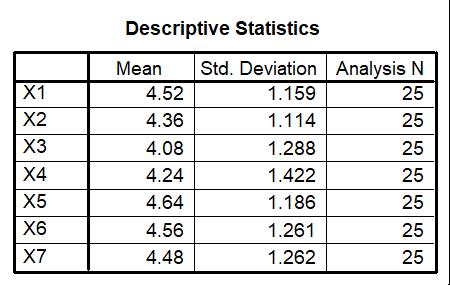
Analisis deskriptif memberikan gambaran tentang data yang kita miliki. Dalam mendeskripsikan data, kita bisa menggunakan berbagi cara. Pada analisis faktor, gambaran diberikan melalui rata-rata (mean) dan standar deviasi (standar deviation) setiap variabel. Cara lain bisa melalui modus, median, range, proporsi, dan indeks variabel kumulatif. Analisis deskriptif, seperti tersaji di atas, belum bercerita apa-apa tentang faktor atau komponen.
Correlation Matrix
Kalau dalam regresi ganda (multiple regression) dihindari, sebaliknya dalam analisis faktor, jusjtru multikolinearitas diinginkan. Malah analisis faktor tidak dapat dilakukan kalau tidak terdapat multikolinearitas.
Multikolinearitas adalah adanya korelasi antar variabel. Pada Output 2, bagian pertama bercerita tentang koefisien korelasi antar variabel. Misalnya, antara antara X1 dan X2, koefisien korelasi adalah sebesar 0,624 dan antara X4 dan X6 sebesar 0,015. Konsep korelasi dapat dibaca pada buku-buku yang relevan. Kedua, berbicara tentang signifikansi korelasi itu. Signifikansinya adalah satu arah (1-tailed). Artinya, Ho adalah korelasi sama dengan nol. Ha-nya adalah nilai mutlak korelasi lebih besar dari nol.

Pada tabel tersebut itu juga terlihat bahwa signifikansi korelasi antara X1 dan X2 adalah 0,000. Artinya, kita bisa menyimpulkan bahwa antara X1 dan X2 ada korelasi, dengan tingkat kesalahan 0,000% atau tingkat keyakinan 100%. Sedangkan antara X4 dan X6 tingkat signifikansinya adalah 0,472. Artinya, bolehlah kita percaya bahwa korelasi antara X4 dan X6 lebih besar dari nol, tetapi tingkat kemungkinan salah menyimpulkan 47,2% (µ=0,472). Dengan tingkat kesalahan seperti ini, signifikansi tidak diterima.
Korelasi antar-variabel yang sama (misalnya X1 dan X1), yang nilainya 1,000, tidak perlu diperhatikan. Karena variabel-variabel tersebut dikorelasikan dengan ‘dirinya-sendiri’. Yang perlu diperhatikan adalah korelasi antar-variabel yang berbeda.
Sebenarnya tidak ada batasan mutlak berapa tingkat kesalahan yang bisa ditoleransi. Akan tetapi, secara umum, tingkat kesalahan di atas 0,05 atau 5%, jarang diterima. Dengan batasan seperti itu, terlihat pada Tabel 5.2 bagian correlation matrix bahwa dari total 21 sel, 10 sel atau 47,62% berisikan korelasi yang signifikan. Dengan persentase sebesar itu, sudah cukup buktikah untuk menyatakan bahwa analisis faktor layak dilakukan pada data Tabel 1? Kita belum bisa memberikan kesimpulan. Persentase itu baru memberi-kan gambaran adanya multikoliearitas. Memang, dengan persentase sebesar itu, secara kualitatif dapat kita simpulkan bahwa analisis faktor layak dilakukan.
KMO and Barlett Test
Kesimpulan tentang layak-tidaknya analisis faktor dilakukan, baru sah secara statistik dengan menggunakan uji Kaiser-Meyer-Olkin (KMO) measure of adequacy dan Berlett Test of spericity.

KMO
Analisis faktor layak dilakukan apabila antar variabel korelasi bivariat lebih tinggi dibanding korelasi parsial. Pengertian kedua jenis korelasi ini bisa dibaca pada buku-buku statistika.
KMO memeriksa kelayakan (appropriateness) analisis faktor. Apabila nilai indeks tinggi (berkisar antara 0,5 sampai 1,0), analisis faktor layak dilakukan. Sebaliknya, kalau nilai KMO di bawah 0,5, analisis faktor tidak layak dilakukan.
Sebagaimana umumnya software statistika, program SPSS menyediakan fasilitas menghitung KMO. Kita tidak perlu repot untuk menghitung secara manual, termasuk membongkar prosedur teknis tentang bagaimana nilai KMO dihitung. Yang penting bagi kita adalah menginterpretasi nilai KMO.
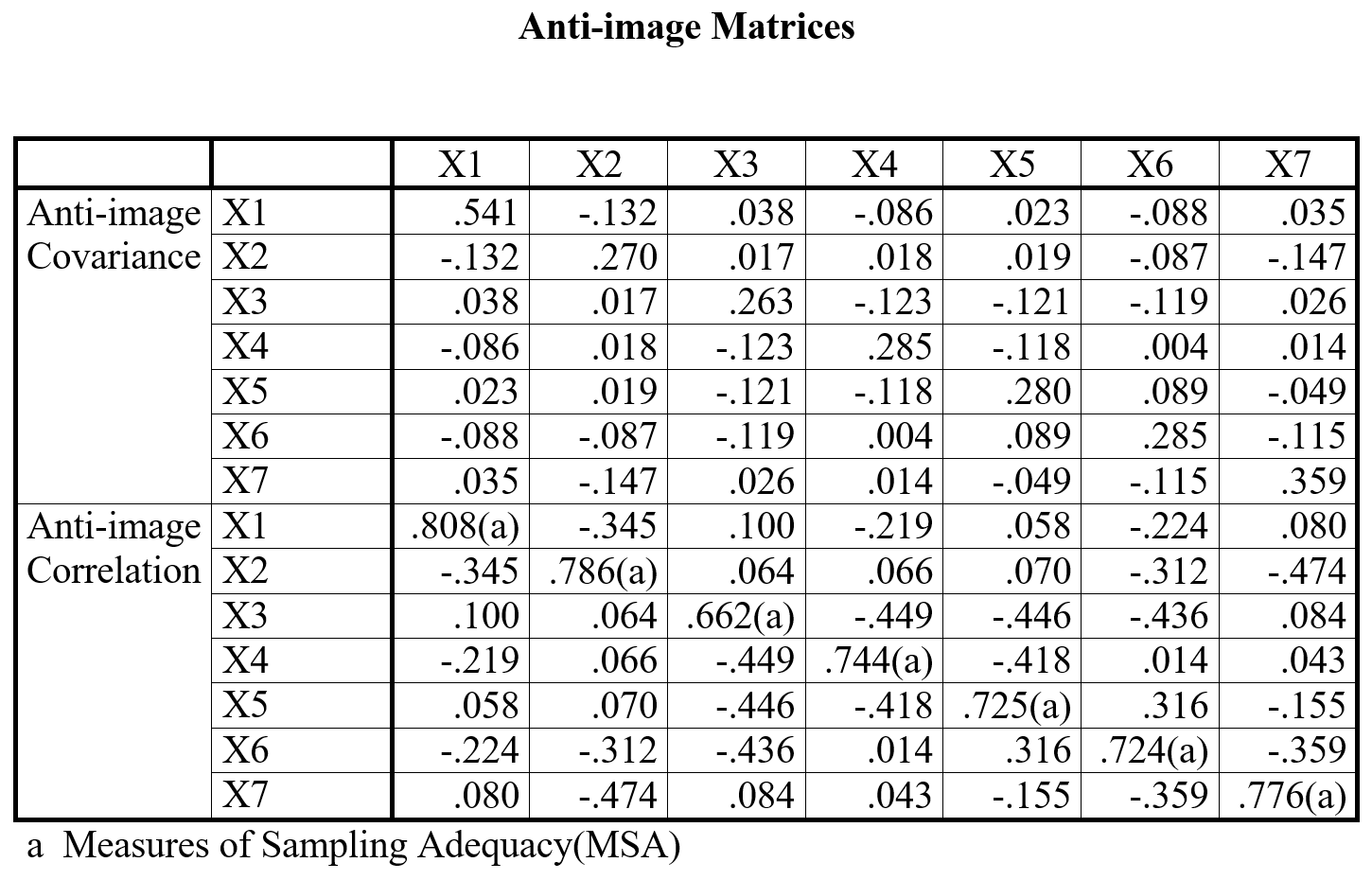
Dari Output 3 terlihat bahwa nilai KMO secara keseluruhan adalah 0,744. Kemudian, pada bagian anti-image correlation, terlihat pula bahwa nilai KMO untuk setiap variabel di atas 0,500. Jadi, analisis faktor layak dilakukan.
Sebenarnya nilai KMO dapat kita cari secara manual dengan memeriksa perbandingan antara korelasi bivariat dan korelasi parsial rumus berikut:
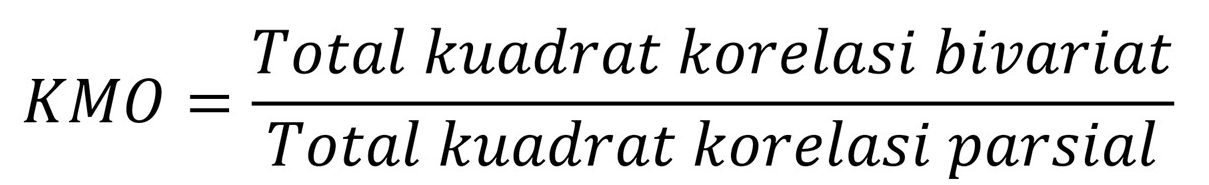
Karena nilai mutlak korelasi parsial sama dengan anti-image correlation, persamaan di atas bisa pula ditulis dengan:
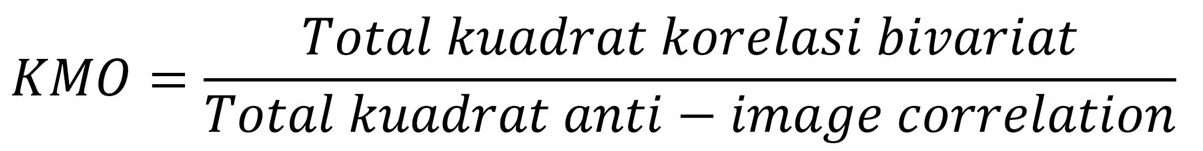
Mari kita buktikan. Dengan menganalisis data korelasi pada matrik korelasi di atas, total korelasi kuadrat X1 adalah: (0.624)2+(0.055)2+(0.048)2+(-0.161)2+(0.591)2+(0.477)2=0.977. Dengan cara yang sama, diperoleh nilai untuk X2 sampai X7 sebagai berikut: 1.647, 1.198, 1.254, 1.336, 1.486 dan 1.361.
Berdasarkan tabel anti-image matrices di bawah maka total kuadrat anti-image correlation adalah: (0.119)2+(0.010)2+(0.048)2+(0.003)2+(0.050)2+(0.006)2=0.237. Dengan cara yang sama, diperoleh nilai untuk X2, X3, X4, X5, X6 dan X7 sebagai berikut: 0.455, 0.611, 0.431, 0.506 dan 0.393.
Perhitungan nilai KMO untuk setiap variabel dan seluruh variabel ditunjukkan di bawah ini. Terbukti secara manual KMO=0.744, sama seperti ditunjukkan output SPSS.
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | TOTAL | |
| Total korelasi kuadrat (A) | 0.997 | 1.674 | 1.198 | 1.254 | 1.336 | 1.486 | 1.361 | 9.306 |
| Total anti-image correlation kuadrat (B) | .237 | .455 | .611 | .431 | .506 | .566 | .393 | 3.198 |
| A+B | 1.234 | 2.129 | 1.809 | 1.685 | 1.842 | 2.052 | 1.754 | 12.504 |
| KMO=A/(A+B) | .808 | .786 | .662 | .744 | .725 | .724 | .776 | .744 |
Barlett Test
Ini merupakan tes statistik untuk menguji Ho: Matrik korelasi sama dengan matrik indentitas. Sebagaimana diketahui, matrik identitas adalah sebuah matrik yang semua nilai adalah 0, kecuali sumbu diagonal bernilai 1, seperti di bawah ini.
| Correlation Matrix Identity | ||||||||
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | ||
| Correlation | X1 | 1.000 | .000 | .000 | .000 | .000 | .000 | .000 |
| X2 | .000 | 1.000 | .000 | .000 | .000 | .000 | .000 | |
| X3 | .000 | .000 | 1.000 | .000 | .000 | .000 | .000 | |
| X4 | .000 | .000 | .000 | 1.000 | .000 | .000 | .000 | |
| X5 | .000 | .000 | .000 | .000 | 1.000 | .000 | .000 | |
| X6 | .000 | .000 | .000 | .000 | .000 | 1.000 | .000 | |
| X7 | .000 | .000 | .000 | .000 | .000 | .000 | 1.000 | |
Keterangan: Matrik identitas ini dibuat secara manual. Analisis faktor dengan SPSS tidak memberikan matrik ini.
Nilai Barlett Test didekati dengan nilai chi-square. Pada Output 3 terlihat bahwa nilai chi-square adalah 101.231, yang untuk derajat kebebasan (degree of freedom, disingkat df) sebesar 21, memiliki signifikansi 0,000. Kesimpulan: Cukup bukti menolak H0 dan menyatakan matrik korelasi berbeda dari matrik identitas, yang berarti terdapat hubungan antar-variabel dengan tingkat kepencayaan 100%.
Anti-image Matrices
Angka-angka dalam matrik ini diambil dari korelasi parsial antar-variabel, yaitu korelasi yang tidak diintervensi oleh variabel lain. Sebagai contoh, dalam SPSS, korelasi parsial antara X1 dan X2 diperoleh dengan memasukkan X2, X3, X4, X5, X6 dan X7 ke dalam space controlling for. Hasilnya adalah 0.345. Kalau korelasi parsial=0.345, kenapa anti-image correlation=-0.345? Jawabannya, anti-image correlation adalah kebalikan korelasi parsial, nilainya dapat diperoleh dengan mengalikan korelasi parsial dengan –1.
Pada matrik di bawah terlihat bahwa pada semua variabel korelasi parsial rendah. Nilai korelasi parsial yang rendah berdampak pada nilai KMO setiap variabel yang tinggi atau di atas 0.500 (lihat sumbu diagonal anti-image matrices yang ditandai dengan huruf ‘a’).
Communalities
Communalities menyatakan varian setiap variable yang dimasukkan (diekstrak) ke dalam faktor-faktor yang dibentuk. Dalam Pada Output 5, terlihat bahwa varian setiap variabel adalah 1,000. Angka ini diperoleh setelah data Tabel 1 distandarisasi.
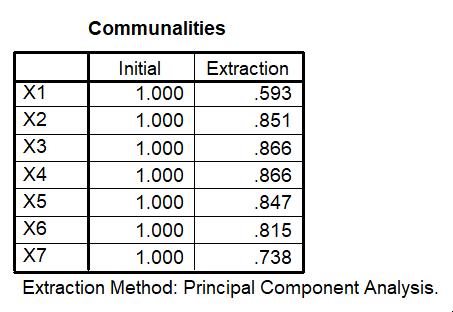
Output di atas menyatakan berapa persen varian yang diekstrak oleh program dari setiap variabel. Varian paling rendah disumbangkan oleh X1 yaitu 59.3% dan tertinggi disumbangkan oleh X3 dan X4 dengan persentase 86.6%.
Total Variance Explained
Output ini sudah memberikan gambaran jumlah faktor yang diekstrak dari ketujuh variabel yang dilibatkan. Memang, kalau ada tujuh variabel yang dilibatkan, akan ada tujuh faktor (disebut juga component) yang diusulkan oleh program. Setiap faktor mewakili variabel-variabel yang dianalisis. Namun, yang sah tidak semuanya. Pada contoh ini hanya ada dua faktor (disebut juga component). Penjelasan tentang kenapa hanya dua faktor yang sah ditunda dulu karena masih ada informasi terkait yang perlu dibahas.
Kemampuan setiap faktor mewakili variabel-variabel yang dianalisis, ditunjukkan oleh besarnya varian yang dijelaskan, yang disebut juga eigenvalue. Sekali lagi, varian yang dimaksud adalah varian variabel-variabel yang sudah distandarisasi. Karena varian setiap variabel adalah satu, maka dalam penelitian kita ini, varian total adalah tujuh karena jumlah variabel adalah tujuh.

Tabel Total Variance Explained
Scree Plot
Scree plot merupakan cara mendeskripsikan eigenvalue secara visual. Pada sisi vertikal, dimasukkan eigenvalue, sedangkan sumbu horisontal mewakili seluruh faktor. Lalu, ditariklah garis yang menghubungkan titik-titik yang mewakili eigenvalue setiap faktor.

Component Matrix
Tabel ini berisikan factor loading (yaitu nilai korelasi) antara setiap faktor dengan variabel-variabel analisis. Dalam tabel ini, hanya dilibatkan dua faktor, padahal ada tujuh faktor yang dihasilkan sesuai dengan jumlah variabel yang dilibatkan. Kenapa hanya dua faktor? Jawabannya kita bahas belakangan.

Rotated Component Matrix
Tabel ini berisikan factor loading (yaitu nilai korelasi) antara setiap faktor dengan variabel-variabel analisis yang sudah dirotasi. Tujuannya adalah mempererat korelasi antara indikator dengan salah satu faktor. Pertanyaannya, bagaimana caranya?
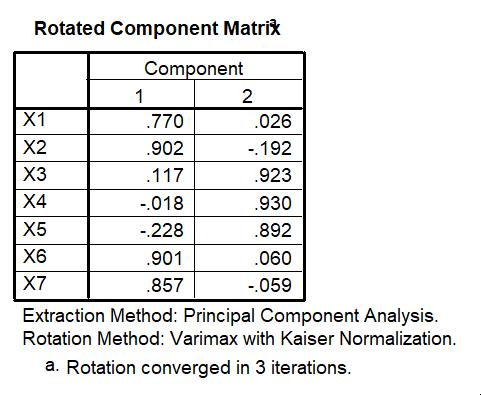
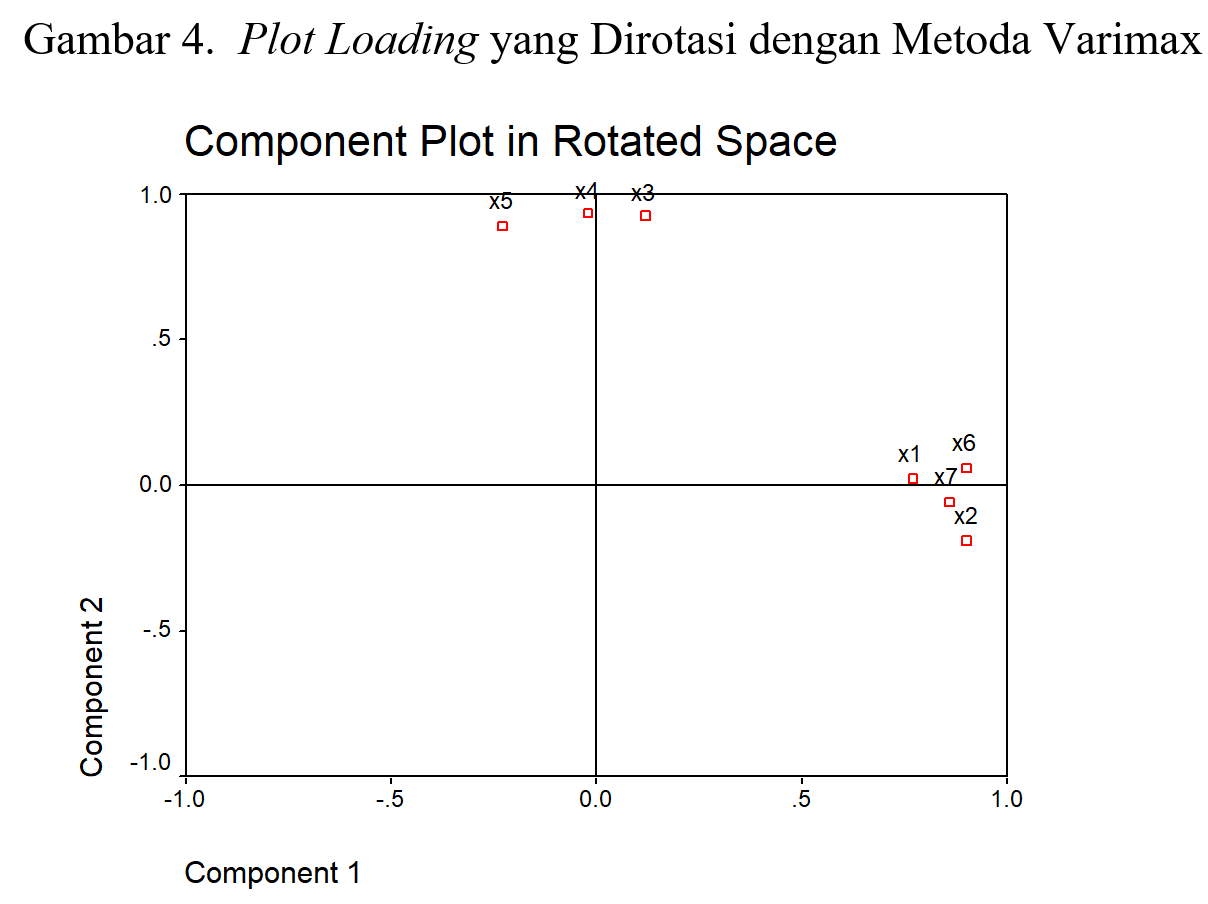
Kalau dipetakan dalam diagram kartesius, dengan menggunakan faktor sebagai sumbu, posisi setiap variabel dapat dilihat seperti pada Gambar 1. Idealnya, setiap variabel mendekat dengan salah satu faktor (dalam plot disebut component). Akan tetapi, dalam Gambar 1, variabel 5 (atau X5) dan variabel 6 (atau X6), memiliki jarak yang tidak jauh berbeda ke faktor 1 dan faktor 2. Dalam component matix juga terlihat bahwa factor loading dengan kedua faktor relatif sama-sama tinggi. Untuk X5, misalnya, terdapat nilai korelasi sebesar -0,575 dengan faktor 1 dan 0,719 dengan faktor 2. Padahal, dengan factor loading-lah kita menyimpulkan menjadi anggota faktor mana sebuah variabel. Idealnya sebuah indikator hanya tergabung pada satu faktor saja.

Gambar 1
Melalui component matrix, terlihat jelas bahwa X1, X2 dan X7 adalah anggota faktor 1 karena ketiga variabel tersebut memiliki korelasi yang tinggi dengan faktor 1, sedangkan dengan faktor 2 korelasinya rendah. Dengan alasan cara yang sama dapat disimpulkan bahwa X3 dan X4 adalah anggota faktor 2. Yang belum bisa disimpulkan secara mantap adalah keanggotaan X5 dan X6. Untuk itulah kita melakukan rotasi.
Rotasi dilakukan dengan memutar (searah ataupun berlawanan dengan jarum jam) kedua faktor yang belum dirotasi. Rotasi dapat dilakukan dengan dua cara. Pertama, rotasi dilakukan dengan tetap mempertahankan sudut kedua faktor sebesar 900. Cara demikian disebut rotasi orthogonal. Ilustrasinya adalah Gambar 5.3. Tujuannya, selain untuk mempertajam perbedaan factor loading setiap variabel untuk kedua faktor, juga untuk mempertahankan keadaan di mana antar faktor-faktor yang diekstrak tidak terdapat korelasi. Quartimax, Varimax dan Equimax adalah tiga metoda rotasi ortogonal yang umum dikenal. Yang paling banyak dipakai adalah Varimax.
Kedua, rotasi tanpa memperhatikan sudut kedua faktor setelah rotasi. Rotasi demikian disebut rotasi oblique. Rotasi ini dapat dilakukan kalau peneliti tidak peduli terhadap ada-tidaknya korelasi antar faktor. Ini terjadi kalau peneliti hanya tertarik pada dimensi yang melandasi variabel (lihat Gambar 5.4). Termasuk di antara metoda rotasi oblique yang dikenal adalah: Oblimin, Promax, Orthoblique, dan Dquart.
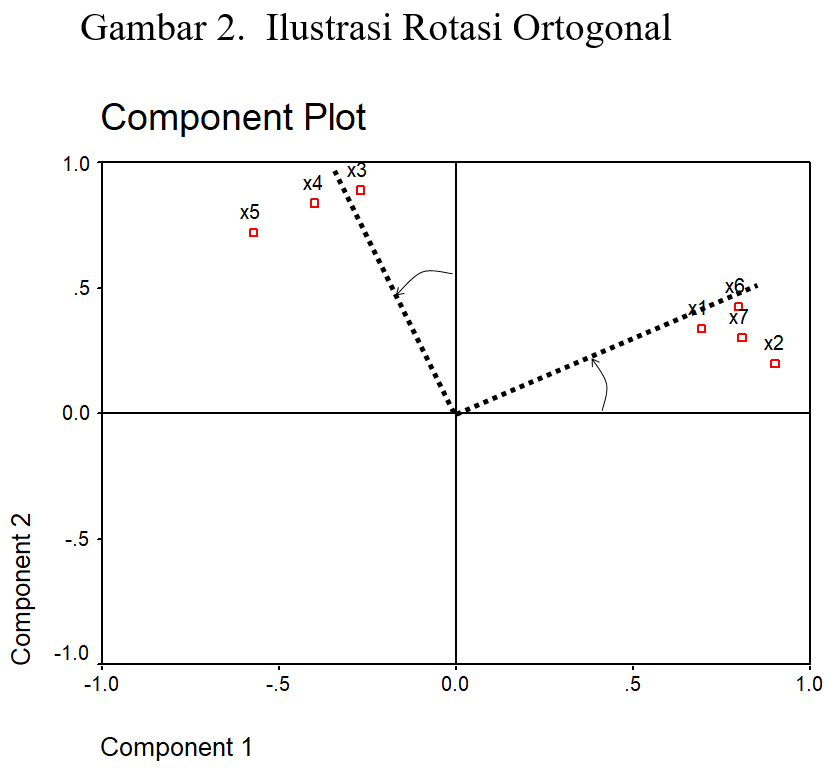
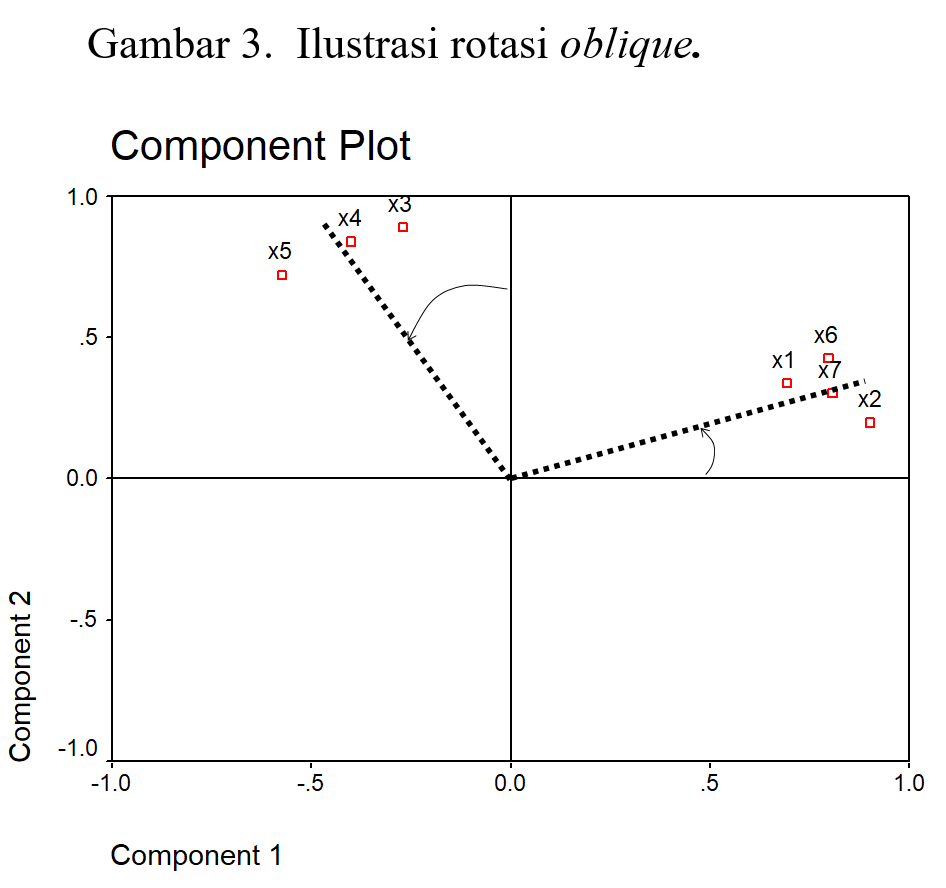
Metoda-metoda di atas bisa ada bisa tidak ada dalam software yang anda pakai. Bisa juga metoda-metoda dalam software anda tidak disinggung dalam buku ini. Harap maklum, karena berkembang dinamis, banyak varian analisis faktor, sehingga sulit untuk merangkum semua metoda dalam satu buku atau software.
Mana yang dipakai? Pertama, tentukan dulu apakah melakukan rotasi secara ortogonal ataukah secara oblique. Setelah itu, lihat mana yang tersedia dalam software anda. Kemudian, lakukan rotasi dengan semua metoda. Metoda yang memberikan hasil terbaik itulah yang dipilih.
Dalam kasus ini, kita melakukan rotasi Varimax, karena setelah metoda rotasi ortogonal lain diujicoba, metoda inilah yang paling baik mendiferensiasi factor loading. Hasilnya dapat dilihat pada Tabel 5.2 bagian rotated component matrix. Berdasarkan factor loadings pada tabel tersebut, dengan mudah kita simpulkan bahwa X1, X2, X6 dan X7 adalah anggota faktor 1, sedangkan X3, X4 dan X5 adalah anggota faktor 2. Kesimpulan yang sama juga terlihat pada Gambar 3. Setiap variabel mendekat dengan salah satu sumbu.
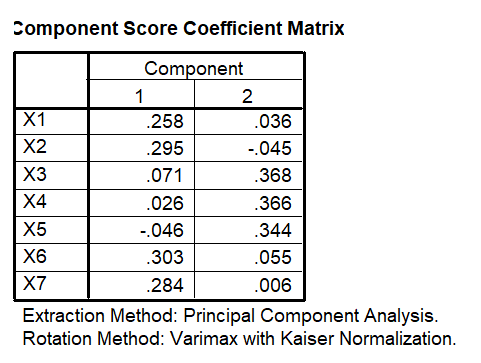
Component Score Coefficient Matrix
Sebenarnya, setiap faktor memiliki persamaan yang mirip dengan regresi linier ganda (multiple-linier regression), hanya dalam persamaan faktor, tidak terdapat konstanta.
Sebenarnya, faktor merupakan turunan sejumlah variabel yang berhubungan. Faktor merupakan kombinasi linier dari variabel-variabel input yang dinyatakan dengan persamaan
![]()
Di mana,
Fj = Skor faktor ke-j
bj = Koefisien skor faktor ke-j (diperoleh dari Tabel 5.2 bagian component score coefficient matrix)
Xsk= Variabel ke-k yang telah distandarisasi.
Kita menggunakan data tabel berikut.
Persamaan untuk faktor 1 adalah:

Dengan persamaan tersebut, kita bisa mencari skor setiap faktor secara manual. Namun, kita tidak perlu melakukannya. Setiap software menyediakan fasilitas untuk menghitung skor setiap faktor. Sekedar untuk mengetahui dari mana asalnya, skor faktor 1 pada responden 1 (lihat Tabel 1), dihitung dengan menggunakan persamaan di atas, di mana nilai-nilai input diambil dari Tabel 5.2 yang berisikan standarisasi nilai-nilai asli.
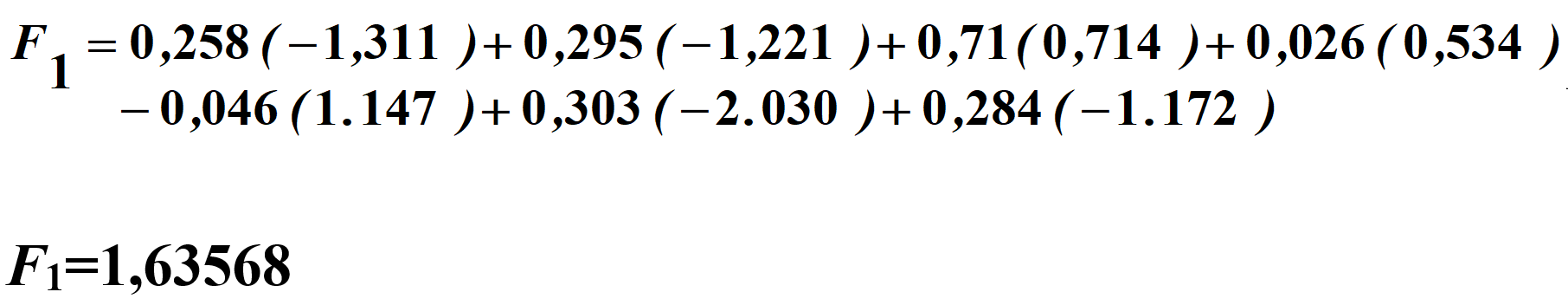
Hasil perhitungan manual (yaitu 1,63568) berbeda sedikit dari hasil perhitungan komputer, akan tetapi perbedaan itu dapat diabaikan karena hanya disebabkan oleh perbedaan angka desimal yang dipakai. Komputer menggunakan angka desimal sampai 15 digit di belakang koma, sedangkan dengan perhitungan manual, hanya tiga digit. Dengan cara yang sama, kalau mau repot, semua skor faktor pada Tabel 1, dapat kita hitung secara manual.
Buat apa skor faktor ini? Kalau memang dibutuhkan, skor-skor faktor yang dihasilkan dapat dipakai untuk menggantikan skor-skor variabel asli.
Component Score Covariance Matrix
Varimax merupakan metoda rotasi ortogonal, yang memperta-hankan sudut perpotongan faktor 1 dan faktor 2 sebesar 900. Dengan sudut demikian, tidak terdapat korelasi antara faktor 1 dan faktor 2. Hal ini tercermin dari covarian antara faktor 1 dan faktor 2 sebesar 0. Covarian antara faktor 1 dan faktor 1 serta faktor 2 dan faktor 2 sebesar 1 bukan hal yang aneh. Itu terjadi pada setiap variabel yang dihubungkan dengan dirinya sendiri.

Berapa Jumlah Faktor yang Diekstrak?
Seperti telah dijelaskan, analisis faktor akan mengusulkan jumlah faktor sebanyak jumlah variabel yang dilibatkan. Namun, jumlah variabel yang valid, mesti lebih kecil dari jumlah variabel input karena dengan analisis faktor kita mencari sejumlah faktor (yang jumlahnya lebih sedikit) yang mewakili variabel-variabel input. Pertanyaannya, berapa jumlah faktor yang valid?
Kalau kita menggunakan SPSS, jumlah faktor yang valid telah ditentukan sendiri oleh program itu. Pada tabel Total Variance Explained, hanya ada dua faktor yang ditunjukkan dalam paparan hasil analisis SPSS tentang communalities, component matrix, rotated component matrix, loading plot, component score coefficient matrix, dan component score covariance matrix. Kenapa? Karena hanya ada dua faktor yang valid.
Sekalipun program telah menyeleksi faktor-faktor yang valid, peneliti perlu tahu apa kriterianya. Menurut Maholtra, keputusan tentang jumlah faktor yang valid dapat didasarkan pada: (1) kebutuhan peneliti sendiri, (2) eigenvalue, (3) scree plot, (4) persentase varian yang dijelaskan, (5) teknik belah tengah, dan (6) tes signifikansi. Bagian selanjutnya menjelaskan teknik-teknik tersebut, kecuali tes signifikansi.
Kebutuhan Sendiri
Umumnya program-program komputer menyediakan pilihan berapa jumlah faktor yang kita butuhkan. Kalau pilihan tersebut tidak kita respon, otomatis program akan menentukan sendiri jumlah faktor yang valid. Namun, sekali pun ditentukan sendiri, jumlah faktor yang ditentukan oleh program, selalu memenuhi kriteria yang diajukan oleh teori.
Kadang-kadang kita menentukan jumlah faktor yang dibutuhkan berdasarkan konsep. Misalnya, konsep ServQual dari Parasuraman et al. (1988) menyatakan bahwa dimensi kualitas layanan ada lima, yaitu keandalan (reliability), aspek-aspek berwujud (tangibles), daya tanggap (responsiveness), jaminan (assurance) dan empati (emphaty). Sudah tentu, kalau kita melakukan analisis faktor terhadap atribut-atribut kualitas layanan, jumlah faktor yang kita minta lima, karena, sekali lagi, konsep mengatakan demikian. Karena itu, kriteria ini disebut juga kriteria konsep.
Contoh kedua. Anda memiliki sejumlah besar variabel (misalnya 20 variabel) image suatu merek. Lalu, anda ingin menganalisis image tersebut dengan metoda sarang laba-laba. Metoda ini membutuhkan delapan dimensi atau variabel. Oleh karena itu, kedua puluh variabel asli perlu direduksi menjadi delapan variabel. Caranya, tentu, dengan analisis faktor yang jumlah faktornya kita yang tentukan.
Eigenvalue
Dengan kriteria ini, maka faktor yang nilai eigenvalue-nya satu atau lebih besar dianggap valid. Sebaliknya, faktor yang eigenvaluenya kurang dari satu tidak valid. Pada Output 7, , terlihat bahwa total variance explained faktor 1 (eigenvalue=3,136) dan faktor 2 (eigenvalue=2,440) yang memenuhi syarat itu. Faktor 3 (eigen-value=0,557), faktor 4 (eigenvalue=0,335), faktor 5 (eigenva-lue=0,195), faktor 6 (eigenvalue=0,192), dan faktor 7 (eigenvalue=0,145) jelas tidak memenuhi syarat karena eigenvalue kurang dari satu.
Scree Plot
Dengan scree plot, kita dapat melihat pola penurunan eigenvalue. Perhatikan garis penghubung nilai-nilai eigenvalue. Kalau setelah sebuah faktor terjadi penurunan tajam, maka faktor yang valid, hanya sampai faktor itu. Pada scree plot terlihat bahwa setelah faktor 2, terjadi penurunan yang tajam ke faktor 3. Oleh karena itu, faktor yang valid hanya sampai faktor 2.
Persentase Varian yang Dijelaskan
Lihat lagi tabel Total Variance Explained. Dengan dua faktor, yaitu faktor 1 dan faktor 2, varian yang dijelaskan secara akumulatif mencapai 79,656%. Dengan persentase akumulatif sebesar itu, sah bagi kita untuk mengekstrak hanya dua faktor. Mungkin ada yang bertanya: “Pak, kalau mengekstrak tiga faktor, bukankah persentase kumulatif lebih tinggi?” Betul, persentase kumulatif varian yang dijelaskan menjadi 87,607%. Tetapi, sumbangan faktor 3 hanya 7,951%. Sumbangan itu masih kurang. Agar valid, sebuah faktor harus menyumbangkan persentase varian yang dijelaskan minimal sebesar rata-rata. Kalau ada tujuh faktor, maka rata-rata dimaksud adalah 100/7 x 100%= 14,29%. Jadi, kalau sumbangan faktor kurang dari 14,29%, untuk kasus ini, faktor tersebut tidak perlu diekstrak.
Bagaimana kalau dalam kasus lain ada 5 faktor? Sumbangan minimal setiap faktor agar diterima adalah 100/5×100%=20%.
Teknik Belah Tengah
Bagi dua sampel secara acak. Lakukan analisis faktor untuk kedua sampel. Sebelumnya minta dulu pada program untuk mengekstrak faktor sejumlah variabel input. Kalau ada enam variabel, maka pada masing-masing subsampel, akan diperoleh enam faktor. Lalu, minta program untuk memberikan skor faktor. Lakukanlah korelasi antar faktor yang nomornya sama dari kedua subsampel, faktor 1 (dari subsampel 1) dan faktor 1 (dari subsampel 2), faktor 2 dan faktor 2, dan seterusnya. Faktor-faktor yang memiliki korelasi yang tinggi dianggap valid. Untuk contoh kasus kita ini, teknik ini tidak dilakukan.
Memberi Nama Faktor
Setelah diperoleh sejumlah faktor yang valid, selanjutnya, kita perlu menginterpretasi nama faktor, mengingat faktor merupakan sebuah konstruk dan sebuah konstruk menjadi berarti kalau dapat diartikan. Interpretasi faktor dapat dilakukan dengan mengetahui variabel-variabel yang membentuknya.
Seperti telah dijelaskan, berdasarkan factor loading, faktor 1 mewakili:
- X1: Aroma ‘sabun aroma buah’.
- X2: Kelembut ‘sabun aroma buah’ di kulit.
- X6: Desain ‘sabun aroma buah’.
- X7: Warna-warni ‘sabun aroma buah’.
Faktor 2 mewakili variabel-variabel:
- X3: Kebersihan kulit.
- X4: Kelembuatan kulit.
- X5: Kehalusan kulit.
Interpretasi nama faktor didasarkan variabel apa yang diwakilinya. Faktor satu dapat kita namakan daya tarik fisik, sedangkan faktor dua sebagai daya tarik manfaat sabun aroma buah.
Interpretasi dilakukan dengan judgement. Karena sifatnya subjektif, maka hasil bisa berbeda kalau interpretasi dilakukan oleh orang berbeda.
Surrogate Variable
Seperti telah dijelaskan, faktor dapat digunakan sebagai variabel baru menggantikan variabel-variabel asli. Akan tetapi, adakalanya peneliti lebih tertarik menggunakan beberapa variabel asli untuk mewakili faktor. Kalau ada dua faktor, pakailah dua variabel, satu variabel mewakili satu faktor. Di antara X1, X2, X6 dan X7, mana yang mewakili faktor 1? Yang factor loading-nya paling tinggi, yaitu X2 dengan r=0,902. Faktor 2 diwakili X4 dengan r=0,930. Kedua variabel pengganti ini disebut surrogate variables.
Pemilihan surrogate variable bukan tanpa masalah. Pertama, kalau dua, tiga atau beberapa variabel memiliki factor loading yang sama atau berbeda sedikit, pemilihan surrogate variable menjadi sulit. Contoh, untuk faktor 1, X2 (r=0,902) sebenarnya bersaing dengan X6 (r=0,901). Masalah ini bisa diatasi dengan memeriksa mana yang paling mewakili secara teori.
Kedua, dengan mewakilkan satu, dua atau beberapa variabel pada satu variabel pengganti, apakah tidak ada informasi yang hilang? Jawabannya pasti ada. Informasi yang hilang ini perlu dipertim-bangkan oleh peneliti sebelum mengambil keputusan.
Summated Scales
Untuk menggantikan variabel-variabel asli, summated scales merupakan gabungan dari variabel-variabel yang berada pada faktor yang sama. Variabel-variabel tersebut digabung dengan dua cara. Pertama, memakai rata-rata semua variabel. Kedua, memakai hasil penjumlahan skor-skor variabel-variabel yang berkoalisi.
Common Factor Analysis
Disebut juga principal axis factoring. Apa yang kita dapatkan dalam principal component analysis, juga tersedia dalam common factor analysis. Kalau data kita dianalisis dengan metoda ini, maka descriptive statistics, correlation matrix, KMO and Barlett’s Test, Anti-image correlation, total variance explained, dan scree plot sama dengan yang dihasilkan metoda PCA. Yang berbeda adalah communalities, factor matrix (dalam PCA disebut component matrix), rotated factor matrix, component score coefficient matrix dan component score covariance matrix. Aspek-aspek yang berbeda itulah yang dibahas selanjutnya.
Prosedur yang digunakan pun sama saja dengan principal component analysis. Bedanya, pada langkah ke-4, pada kotak dialog extraction (yang diperoleh dengan meng-klik menu desciptive pada kotak dialog factor analysis) pilih principal axis factoring. Langkah sebelum dan setelahnya sama saja.
Langkah-langkah:
- Dari menu utama, pilih analyze, kemudian data reduction, lalu klik factor analysis.
- Highlight semua variabel, lalu masukkan ke dalam ruang variabels.
- Klik menu descriptive, akan tampak kotak dialog seperti di bawah ini, lalu beri tanda dengan meng-‘klik’ pilihan-pilihan univariate descriptive, initial solution, coefficient, dan KMO and Barlett test of Sphericity.
- Klik menu descriptive. Lalu, pada kotak dialog yang ditampilkan, pilih principal axis factoring, lalu kembali dengan meng-‘klik’ continue.
- Klik menu rotation. Tandai pilihan-pilihan varimax, rotated solutions dan loading plot(s).
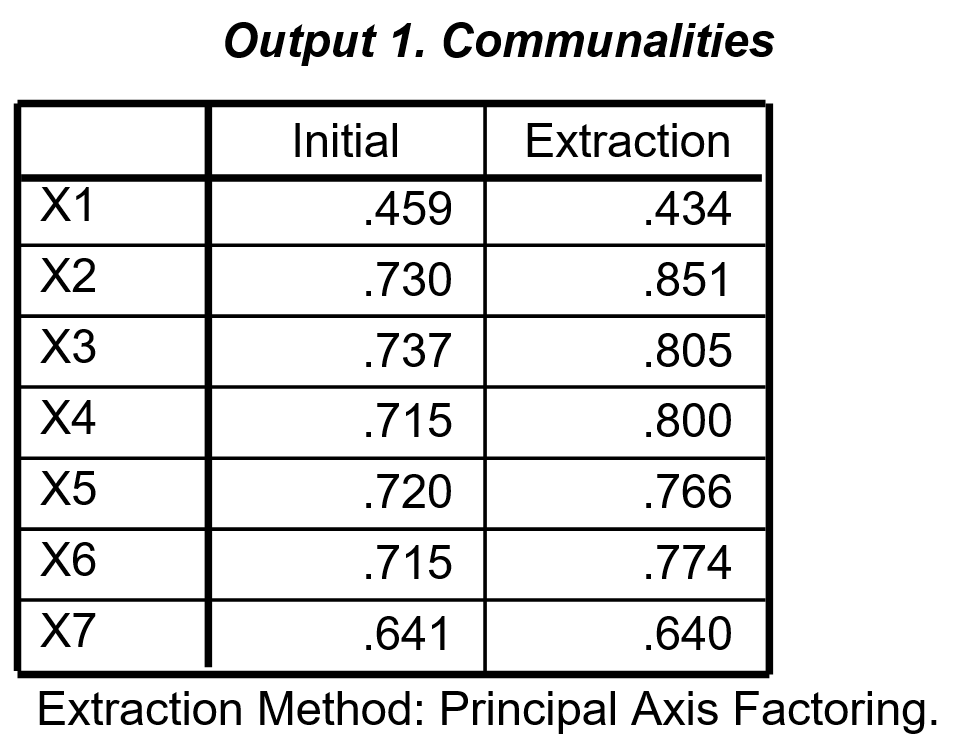
Communalities
Seperti kita ketahui, communalities adalah total variance yang dijelaskan oleh faktor yang diekstrak. Cara mengetahui berapa besar yang diekstrak (extraction) sama saja dengan metoda PCA. Yang mau dikemukakan dalam penjelasan ini adalah kenapa varian awal (initial) tidak sama dengan satu sebagaimana dalam PCA. Jawabnya, dalam PCA, yang dipakai adalah varian total. Untuk data yang distandarisasi, besarnya satu. Sedangkan dalam common factor analysis, yang dipakai adalah common variance.
Common variance adalah total variance dikurangi specific variance dan error variance. Jadi, wajar saja kalau common variance (disebut initial) kurang dari satu (Output 1).
Rotated Factor Matrix
Kesimpulan yang kita ambil dari rotated factor matrix ini sama saja dengan yang sebelumnya. Yang berbeda hanyalah factor loading.

Factor Score Coefficient Matrix
Interpretasi sama saja dengan PCA, yang jelas memang koefisien-koefisien berbeda. Otomatis persamaan kedua faktor yang diekstrak juga berbeda. Sebagai konsekuensinya, skor faktor juga berbeda.

Pertanyaannya, kalau memang common factor analysis juga memberikan hasil yang diberikan PCA (di mana sebagian aspek sama dan sebagian aspek lainnya berbeda), apa yang menjadi pertimbangan kita untuk memilih salah satu di antaranya?
Kalau tujuannya adalah untuk mengetahui dimensi-dimensi yang mendasari variabel-variabel input, pakailah common factor analysis. PCA juga bisa memberikan hasil itu, akan tetapi metoda ini lebih akurat. Common factor analysis juga dapat memberikan faktor, lengkap dengan skornya kalau ingin dijadikan sebagai variabel baru menggantikan variabel-variabel asli. Namun, kalau itu tujuannya, pakailah PCA.
Confirmatory Factor Analysis
Analisis faktor konfirmatori, terjemahan dari confirmatory factor analysis (CFA), adalah teknik untuk menguji apakah variabel-variabel pengamatan merefleksikan konstruk yang tempatnya bergabung. Analisis faktor konfirmatori (CFA) dan analisis faktor eksplorasi (EFA) adalah sama-sama analisis faktor, tetapi dalam analisis faktor eksplorasi (EFA), data dieksplorasi untuk menemukan jumlah faktor yang melandasi variabel-variabel yang dilibatkan.
Seperti telah dijelaskan, EFA mengidentifikasi jumlah faktor sesuai jumlah variabel. Walaupun pada akhirnya hanya sejumlah faktor yang sah, korelasi antara setiap variabel dengan semua faktor dihitung dalam analisis … read more
Keterbatasan Analisis Faktor
Walaupun tampak canggih, analisis faktor bukan segalanya. Teknik ini tidak terlepas dari berbagai kelemahan. Keterbatasan utama adalah tingginya subjektifitas dalam penentuan jumlah faktor, interpretasi setiap faktor dan pemilihan rotasi.
Keterbatasan lainnya, tidak ada kriteria untuk menyatakan bahwa hasil analisis faktor betul-betul sah. Hasil KMO dan Barlett’s test saja bisa bertolak belakang. Pada sebuah kasus, bisa saja nilai KMO di bawah 0,500, akan tetapi nilai Barlett’s test signifikan.
Batas nilai KMO sendiri tak lepas dari kelemahan. Apa bedanya 0,499 dan 0,500? Tetapi, dengan kekurangan hanya 0,001, sebuah analisis faktor yang nilai KMO-nya 0,499, menurut uji ini, sudah pasti dinyatakan tidak layak.
Jalan keluarnya, kalau ukurannya besar, misalnya 150 orang, coba membagi sampel ke dalam tiga subgrup, yang ukuran masing-masing 50 orang dan anggotanya dipilih secara acak. Lalu, lakukan analisis faktor pada masing-masing grup. Kalau hasil masing-masing subgrup sama, bolehlah kita yakin bahwa analisis faktor yang kita lakukan akurat.
Referensi
Eliot, A.J., & McGregor, H.A. (2001). A 2 × 2 achievement goal framework. Journal of Personality and Social Psychology, 80(3), 501–519. DOI: 10.1037/0022-3514.80.3.501.
Hair, J.F., Black, W.C., Babin, B.J. and Anderson, R.E. (2014). Multivariate Data Analysis. 7th Edition, Pearson Education, Upper Saddle River.
Maholtra, N. K. (2020). Marketing Research An Applied Approach. Prentice-Hall, Inc.
Parasuraman, A., Zeithaml, V.A. and Berry, L.L. (1988) SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. Journal of Retailing, 64, 12-40.