Last updated on May 23, 2023 by Bilson Simamora
Dalam ANCOVA terdapat satu variabel dependen dengan satu atau beberapa variabel kategorikal dan satu atau beberapa variabel numerik. Setiap pengamatan harus independen, artinya setiap partisipan hanya bisa masuk ke dalam satu grup. Syarat ini harus diperhatikan saat peneliti mendesain penelitian.
ANCOVA juga mengharapkan eror residual (residuals error) berdistribusi normal. Syarat lain yang harus dipenuhi adalah homogenitas varian/varian eror, homoskedastisitas, dan linieritas hubungan kovariat dengan variabel dependen.
Homoskedastisitas berbicara tentang persebaran residual, apakah tersebar merata (homoskedastis) atau tidak merata (heteroskedastis) pada setiap tingkat variabel dependen. Prinsip linearitas bertujuan memastikan apakah hubungan antara variabel independen metrik (yang dinamakan kovariat) dengan variabel dependen memiliki hubungan linier ataukah non-linier.
Sebagai bentuk pembelajaran, download dan buka file Ancova.sav melalui link ini. Kita ingin memeriksa apakah indeks prestasi kumulatif (IPK) dipengaruhi oleh minat terhadap jurusan dan kecerdesan intelektual (intellectual question atau IQ). Pada contoh ini, IPK adalah variabel dependen, minat dan IQ adalah variabel independen. Minat yang berifat kategorikal (tidak berminat, berminat, sangat berminat) disebut faktor, sedangkan IQ adalah kovariat yang berskala numerik.
Analisis dalam SPSS mengikuti prosedur:
- Analysis>General Linear Modelling>Univariat.
- Lalu, pada kotak dialog yang ditampilkan, masukkan IPK pada sel ‘Dependent Variables’, minat pada sel ‘Fixed Factor(s)’, dan IQ pada sel Covariate(s) (Gambar 1).
- Selanjutnya, klik Save. Pada kotak dialog SPSS, tandai Unstandardized di bawah Predicted Values dan Unstandardized di bawah Residuals (Gambar 2).
- Kemudian, pada menu Options, tandai Descriptive, Parameter Estimates, Homogeneity Test dan Residual Plot (Gambar 3). Output-nya disimpan dulu dengan nama file ‘Output-Ancova.spv’ atau nama lain menurut keinginan anda.

Prosedur ANOVA
Memeriksa Syarat Ancova
Normalitas Residual
Setelah analisis dilakukan, kita kembali data. Di sana kita temukan variabel baru yang diberikan SPSS, yaitu residual, yang oleh program diberi nama RES_1. Variabel ini merupakan selisih antara nilai IPK prediksi (PRE_1) dengan IPK hasil observasi (ipk). Untuk mengetahui apakah variabel ini berdistribusi normal, lakukan prosedur: Analysis>Descriptives>Explore. Masukkan Residual for ipk ke sel Dependent List, klik menu Options dan tandai Normality plots with test.

Hasil uji normalitas disajikan pada Output 1. Berdasarkan dua uji yang dilakukan, yaitu Kolmogorov-Smirnov (nilai=0.131, sig.=0.200) dan Shapiro-Wilk (nilai=0.982, sig.=0.879) tidak terdapat cukup bukti untuk menolak Ho bahwa residual dependen variabel berdistribusi normal.
Homogenitas Varian antar Kelompok
Kembali ke file Output_Ancova.spv. Homogenitas varian/varian eror diperiksa melalui uji Lavene. Berdasarkan Output 2 terlihat bahwa uji Lavene (F=0.097, p-value=0.907) tidak dapat menolak Ho bahwa error variances pada ketiga kelompok adalah sama.
Output 2

Uji Homoskedastisitas
Homoskedastisitas dapat kita secara visual dengan membuat grafik scatter-plot antara predicted value dan residual. Kali ini homoskedastisitas tidak terdapat pada file Output_Ancova.spv. Oleh karena itu, kita harus buat lagi. Untuk itu lakukan prosedur berikut: Graph>Chart Builder>OK.
Dari Gallery pilih Scatter/Dot. Kemudian, drag Predicted Value for ipk ke Sumbu X, lalu drag Residul for ipk ke sumbu Y. Hasilnya kita peroleh seperti grafik di bawah ini.
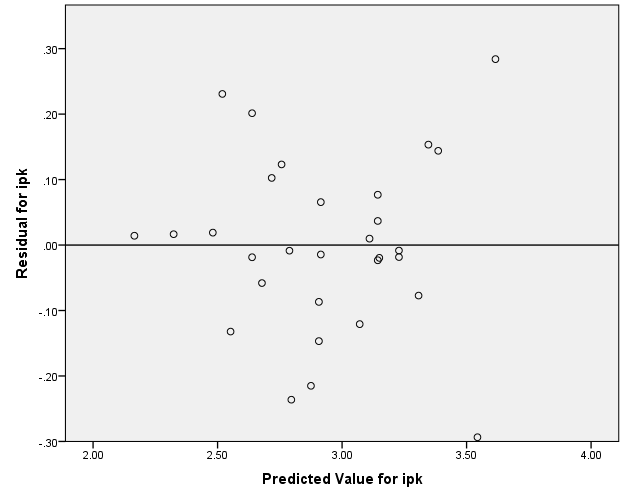
Secara visual ada indikasi bahwa prinsip homoskedastisitas terpenuhi, karena persebaran nilai residual pada level predicted value for ipk merata pada setiap level “predicted value for ipk”. Untuk membuktikan secara statistik, kita dapat menggunakan uji Glejser. Caranya adalah dengan menjadikan nilai absolut residual value sebagai dependent variabel dan ‘minat’ serta ‘iq’ sebagai variabel independen. Oleh karena itu harus menfaatkan dulu fasilitas Transform pada SPSS untuk memperoleh nilai absolut residual values dengan cara yang dijelaskan di sini. Pada contoh ini, nilai absolute residuals dijadikan variabel baru dengan nama Abs_Res.
Prosedurnya: Analysis>General Linear Modelling>Univariate. Masukkan ‘Abs_Res’ sebagai variabel dependen, ‘minat’ pada sel Fixed factor(s) serta ‘iq’ pada sel Covariate(s). Jangan lupa memilih Parameter estimates melalui menu Options. Hasil seperti berikut.

Dari tabel di atas terlihat bahwa‘minat’ dan ‘iq’ tidak dapat dipakai sebagai variabel independen bagi nilai residual absolut (Abs_Res) karena nilai t keduanya memiliki signifikansi melebihi ∝=0.05. Dengan demikian dapat dikatakan bahwa persamaan Ancova memenuhi prinsip homoskedastisitas.
Liniearitas juga tidak terdapat pada Output_Ancova.spv. Untuk memeriksanya, bila hanya ada satu kovariat, pertama-tama, kita dapat membuat grafik yang menghubungkan variabel dependen dan kovariat. Dengan prosedur pembuatan grafik pada SPSS, yang sudah dijelaskan di atas, kita dapat memperoleh grafik seperti di bawah ini.
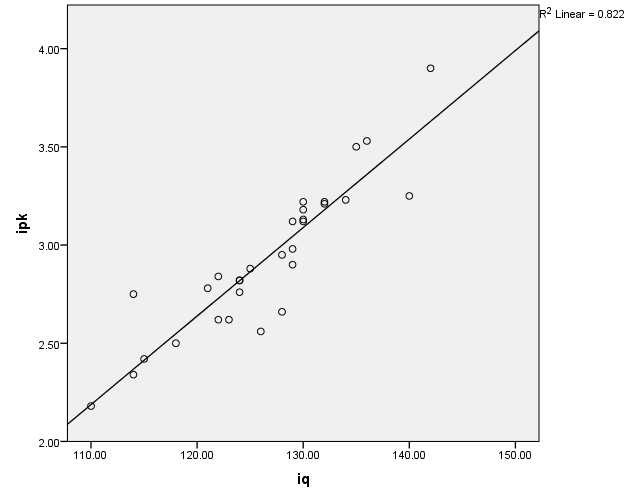
Pada grafik tersebut terlihat bahwa titik-titik yang menandai koordinat (X,Y) setiap observasi, yang didasarkan pada iq (absis atau X) dan ipk (ordinat atau Y), mengumpulkan di sekitar sebuah garis lurus. Hal ini mengindikasikan adanya hubungan linier antara kedua variabel. Betulkah linier? Kita uji dengan mencari pengaruh IQ terhadap IPK.
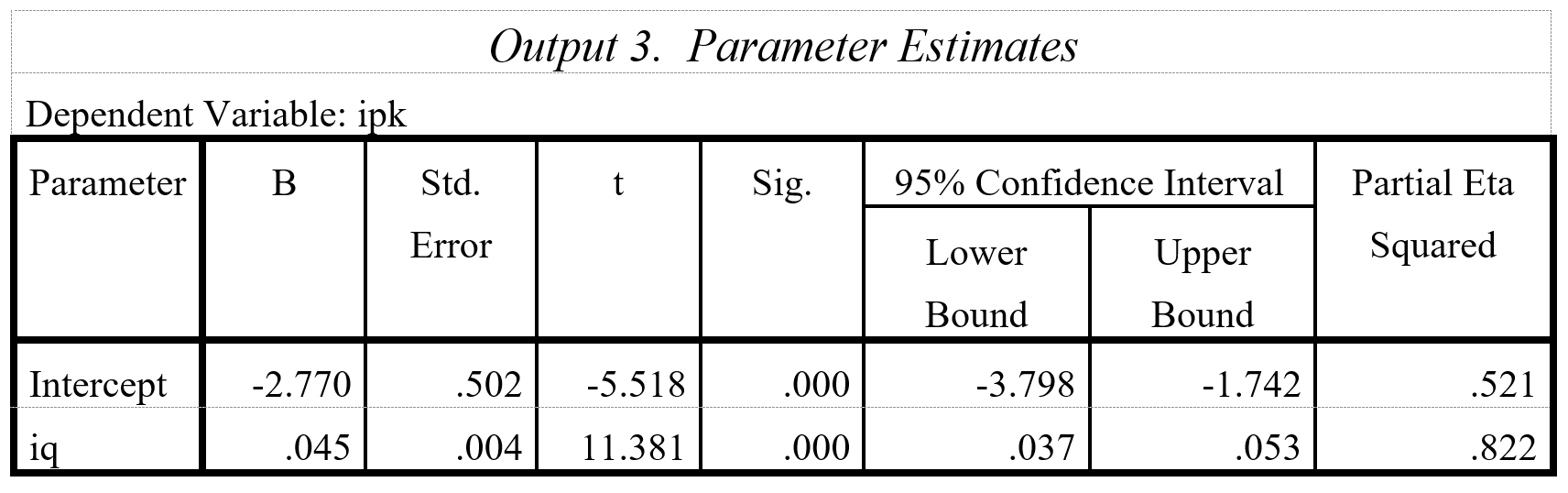
Prosedur: Analysis>General Linear Modelling>Univariat. Masukkan ‘ipk’ sebagai variabel independen dan ‘iq’ sebagai kovariat. Pada menu Options tandai parameter estimates. Hasil pada Output 3 menunjukkan bahwa ‘iq’ berpengaruh signifikan (t=11.381, sig.=0.000) terhadap ‘ipk’.
Interpretasi Hasil ANCOVA
Setelah syarat-syarat normalitas, homogenitas, homoskedastisitas, dan linieritas terpenuhi, kita dapat melakukan ANCOVA. Mari kembali ke file Output_Ancova.spv. Kita lihat hasil Test of Between-Subject Effects. Perhatikan nilai F.
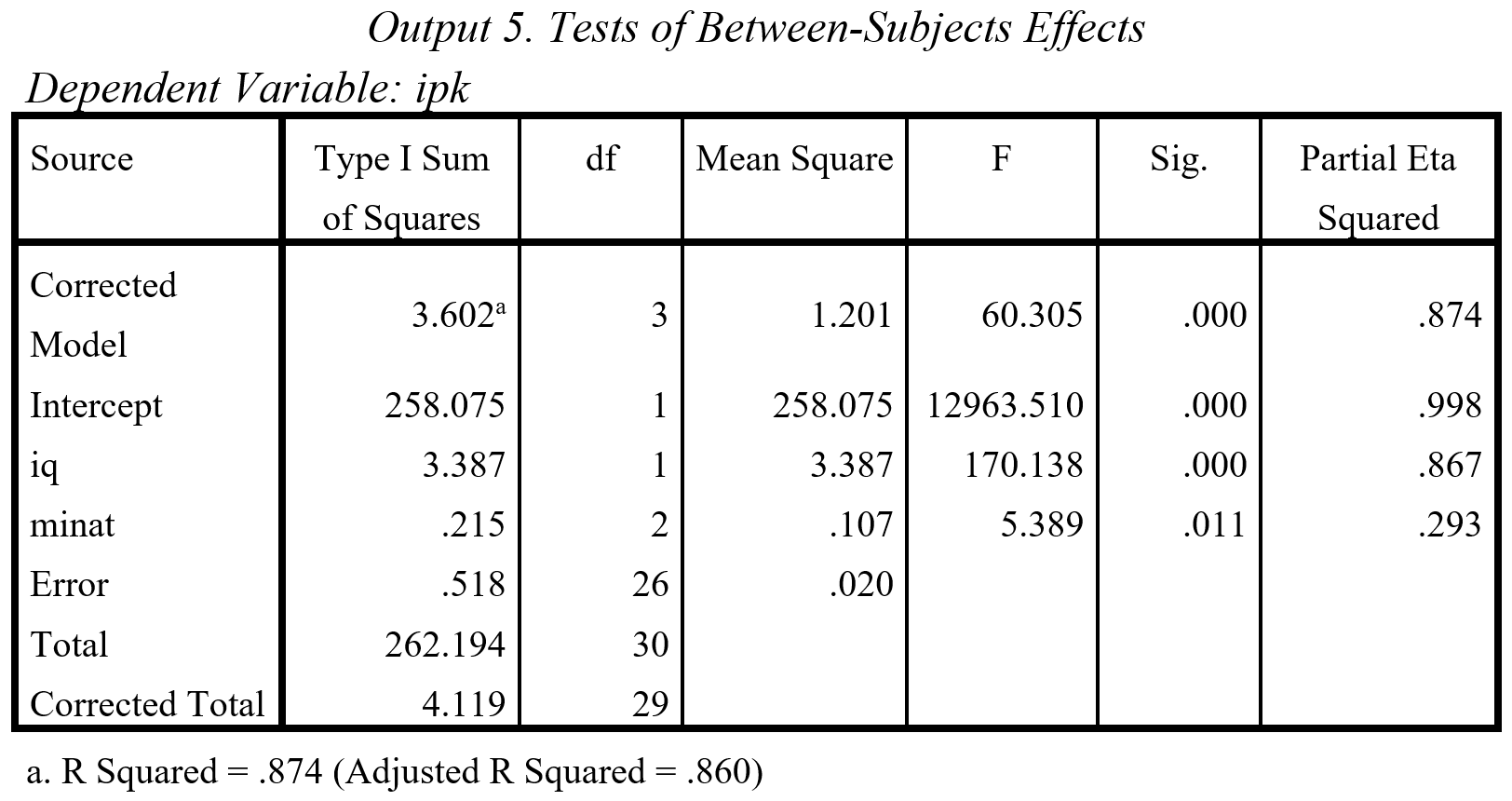
Berdasarkan Output 5, kesimpulan berdasarkan nilai F variabel independen atau interaksinya (kalau ada) adalah sebagai berikut. Pertama-tama, pada variabel ’minat’, perbedaan rata-rata ’ipk’ antar subjek, yang di-adjusting berdasarkan variabel ’minat’ adalah signifikan [(2,26)=5.389, sig.=0.011]. Artinya, terdapat perbedaan IPK berdasarkan minat.
Kenapa di-adjusting? Karena ada faktor lain yang berkaitan dengan perbedaan ’ipk’ antar partisipan selain minat, yaitu ’iq’. Variabel ini membedakan ’ipk’ antar partisipan dengan signifikan [F(1,26)= 170.138, sig.=0.000].
Untuk lebih memahami ’adjusting’ dimaksud, mari kita lihat pengaruh ’minat’ dengan cara mengeluarkan ’iq’. Kita me-run ulang program SPSS. Ulangi prosedur analisis yang dijelaskan di awal seksi ini. Dengan mengeluarkan ’iq’ dari sel Covariates, maka diperoleh hasil di bawah ini (Output 6).
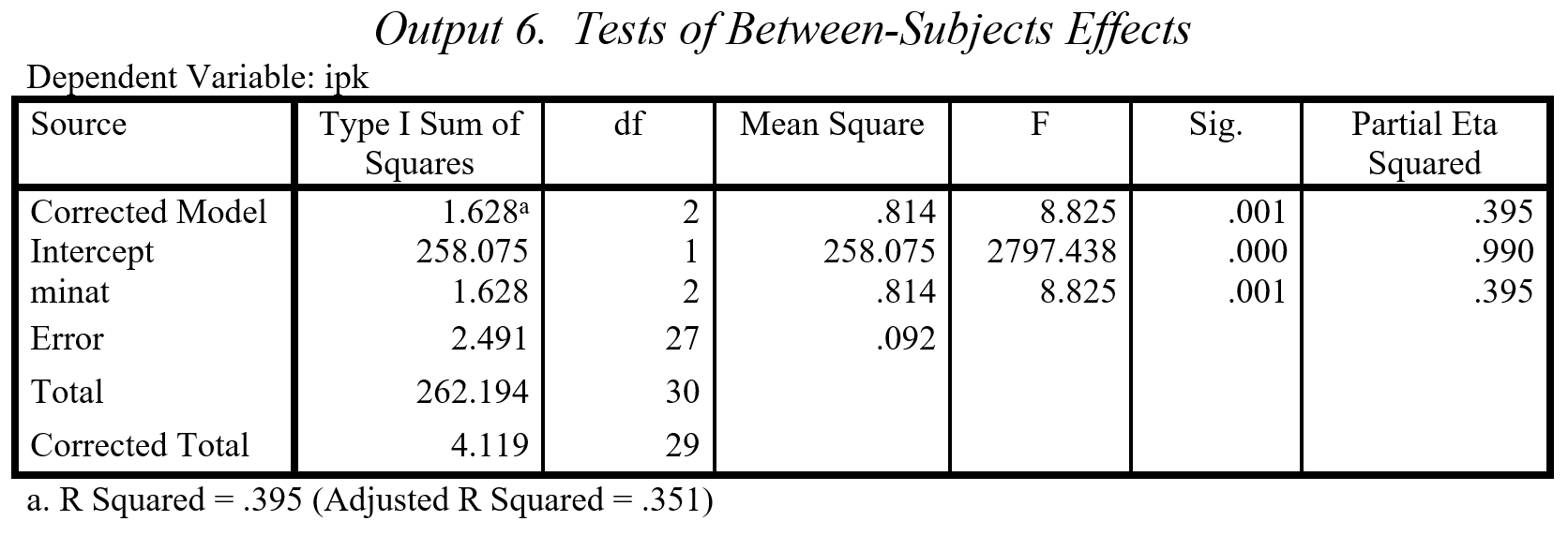
Pada Output 6 terlihat bahwa ‘ipk’ berbeda berdasarkan ‘minat’ dengan nilai F=8.825 dan p-value=0.001, sebelumnya adalah nilai F=5.389 dan p-value=0.011 (Output 5). Nilai F meningkat kala F sendirian, namun hanya dapat menjelaskan 39.5% varian ‘ipk’ (adjusted R2=35.1%). Padahal, dengan memasukkan ‘iq’ sebagai kovariat, model ANCOVA dapat menjelaskan 87.4% varian ipk (adjusted R2=86%). Jadi, secara statistik, ‘iq’ mengurangi pengaruh ‘minat’. Karena perbedaan berpengaruh itulah pengaruh diferensiasi ‘minat’ terhadap IPK disesuaikan (di-adjusting).
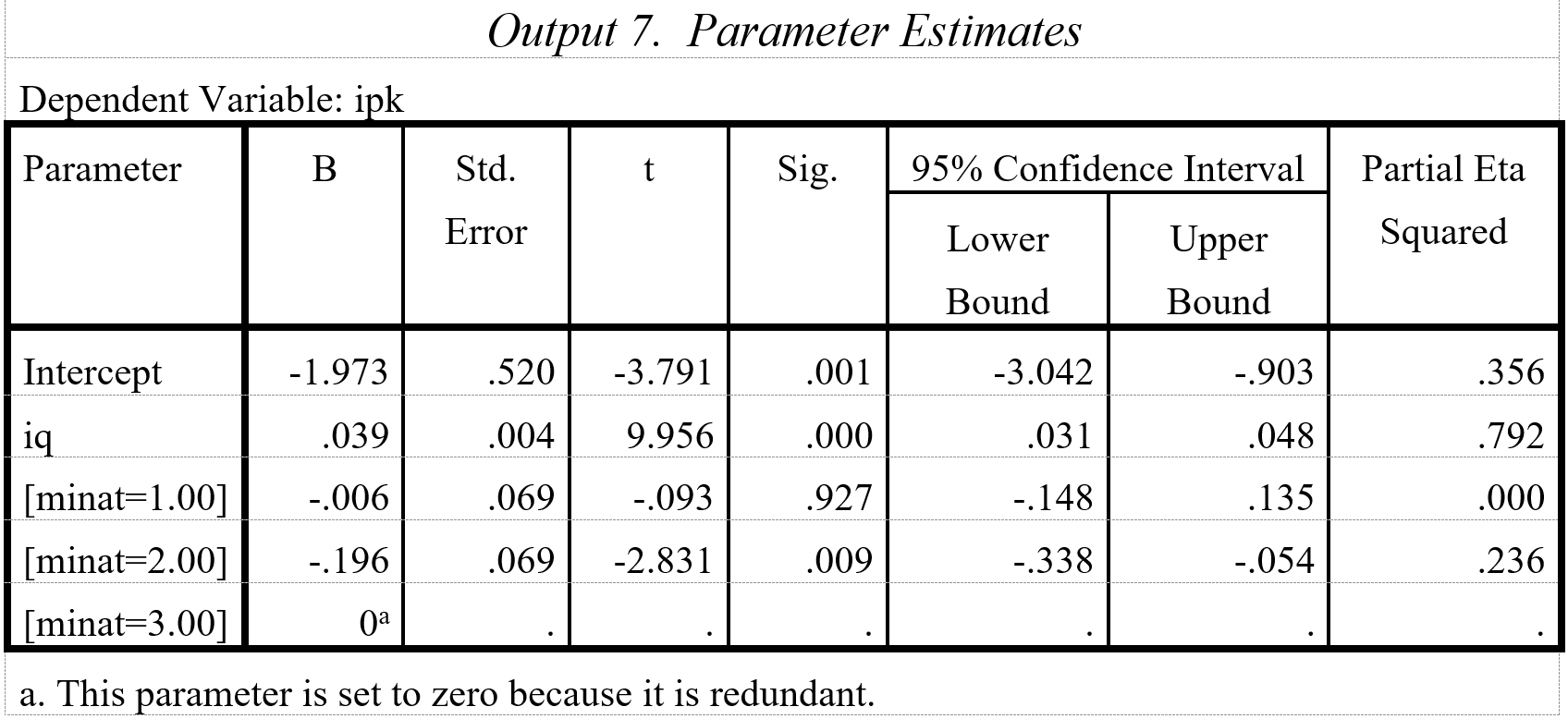
Untuk membentuk persamaan linier ANCOVA, kita menggunakan hasil pada Output 7. Berdasarkan hasil ini, kita bisa membentuk tiga persamaan linier, di mana setiap grup partisipan memiliki persamaan sendiri.
Grup 3 ‘sangat berminat’ (minat=3): ipk= -1.973 + 0.039
Grup 1 berminat(minat=2): ipk = – 1.973 + 0.039 – 0.006 minat
Grup 2 tidak berminat (minat=1)): ipk = – 1.973 + 0.039 – 0.196 minat
Pada ketiga persamaan terlihat bahwa iq berpengaruh signifikan (t=9.956, sig.=0.000). Partial squared eta = 0.792 menunjukkan bahwa variabel ini dapat menjelaskan 79.2% varian ‘ipk’. Program menjadikan grup 3 (sangat berminat) sebagai ‘base line’ atau keadaan normal.
Grup 2 (tidak berminat) dianggap sebagai gangguan atau penyimpangan terhadap ‘base line’, yang menurunkan ‘ipk’ sebesar – 0.196 atau sebesar koefisiennya. Penurunan ini dianggap signifikan (t= -2.831, sig.=009). Penurunan minat dari ‘sangat berminat’ (Grup 3) menjadi ‘berminat’ (Grup), menurunkan ‘ipk’ sebesar koefisiennya, yaitu -0.006. Penurunan ini dianggap tidak signifikan (t=-0.093, sig.=0.927) (Catatan: Angka 1, 2, dan 3 pada grup berbasis minat hanya label, di mana: berminat=1, tidak berminat=2, sangat berminat=3. Urutan angka tidak perlu dipersoalkan).
Apa yang dimaksud titik berangkat atau keadaan normal itu? Dalam regresi yang melibatkan variabel kualitatif kita bisa menentukannya sendiri. Tetapi, dalam ANCOVA ini, model menentukannya. Ilustrasi berikut diharapkan menjelaskannya. Penjualan es krim di sebuah toko rata-rata 600 buah per hari. Namun, pada keadaan hari hujan, penjualan turun menjadi 200 buah per hari. Dalam ilustrasi ini, hari hujan adalah keadaan khusus, bukan keadaan normal. Jadi, kita tidak menyatakan begini: Penjualan es krim adalah 200 buah per hari, tetapi kalau tidak hujan adalah 600 buah per hari.
MANOVA
MANOVA digunakan apabila peneliti ingin melihat pengaruh satu atau lebih variabel independen yang bersifat kategorikal, yaitu menggunakan skala nominal atau ordinal, terhadap dua atau lebih variabel variabel dependen yang berskala numerik. Teknik ini tidak sama dengan multiple ANOVA. Ada maksud lain MANOVA yang tidak dapat diberikan oleh multiple ANOVA … read more